事件的起因是同学推给了我一个突破百度网盘的工具,里面是Aria2和一个获取直接下载链接的油猴脚本。我和y就一起研究了下。
研究脚本的过程就不多说了,白活一天踩坑无数。直接看成果。
在web端选中一个文件点下载,用浏览器network或者bp抓包都可以。浏览器通过GET数次请求百度服务器的API,参数包括uk(其中一个用户标识)、时间、文件列表等。最终获得了一个内容分发服务器的链接。请求这个链接,返回内容才是真实的下载地址。
浏览器network比较直观。
在请求download控制器的时候,返回结果: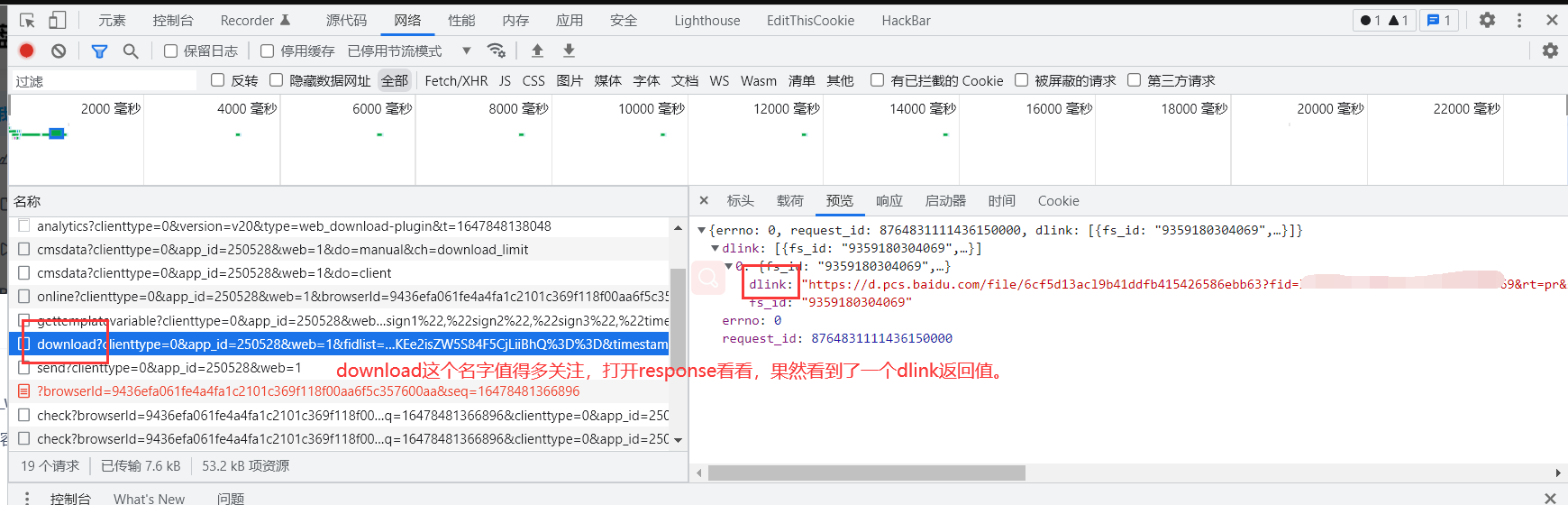
这个dlink是个链接。截取到这个dlink1
https://d.pcs.baidu.com/file/6cf5d13acl9b41ddfb415426586ebb63?fid=*************&rt=pr&sign=******************%2BOauEvuwF6%2FGO84Q%3D&expires=1h&chkv=1&chkbd=1&chkpc=et&dp-logid=******&dp-callid=0&dstime=1647840936&r=998219680&vip=2
通过脚本的研究,继续请求这个地址。带上user agentpan.baidu.com。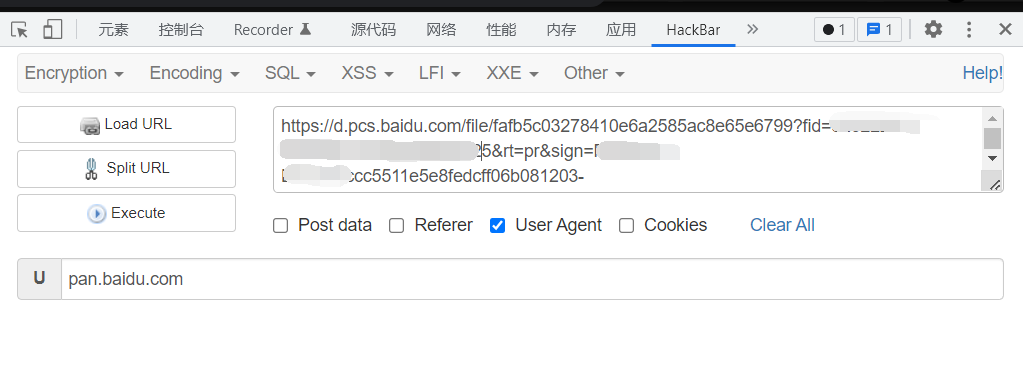
请求这个地址返回的是一个长网址,这个是真实的下载链接。把这个链接复制到IDM或者Aria2里面就可以多线程分块下载了,提高传输速度。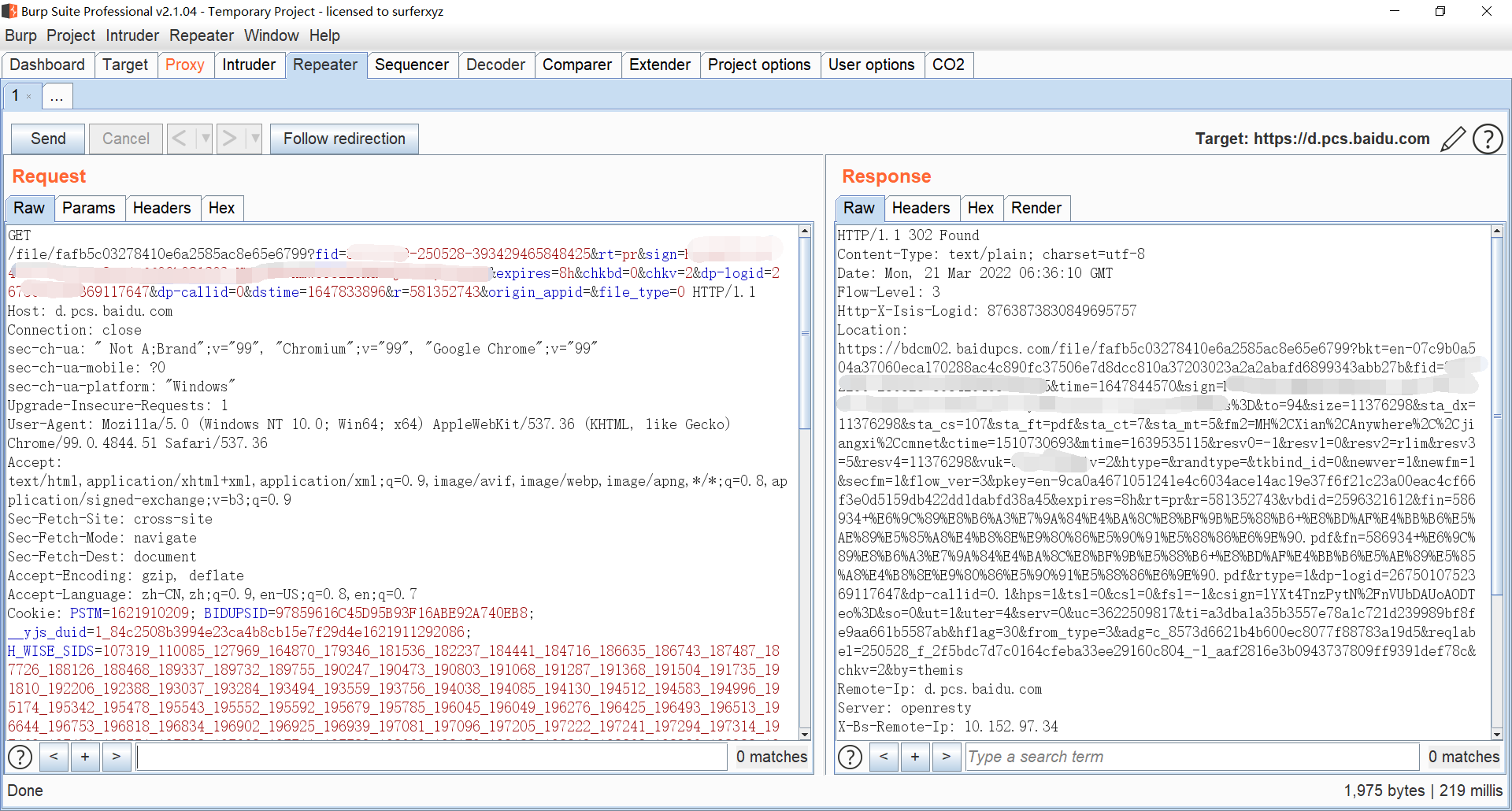
所以猜测第一次获取到的短地址是内容分发服务器,请求内容分发服务器,内容分发服务器把下载内容以流的形式缓存在不同的下载服务器上以供下载,防止网络阻塞。
我又脑洞大开浅薄的猜测了一下,会员的节点服务器是特定的,不会限流,如果通过超级会员来请求,请求到的直接下载地址就是快的服务器。这个猜测需要得到验证。